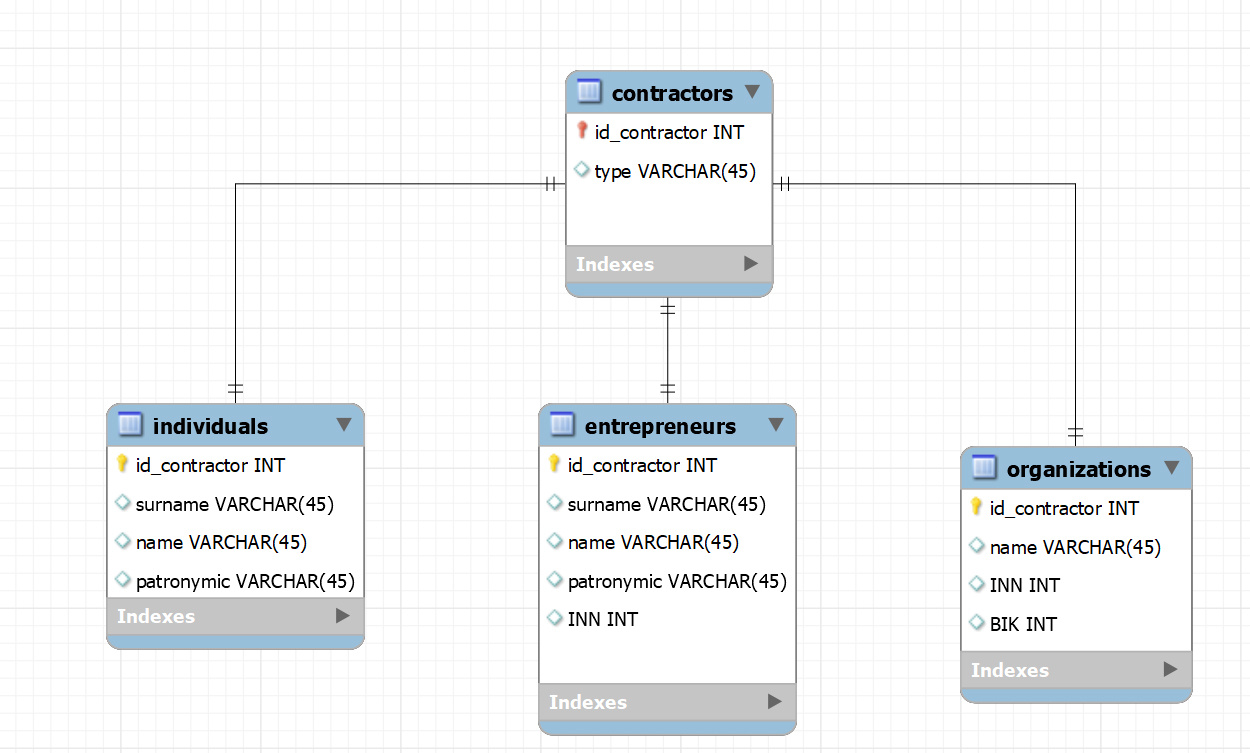
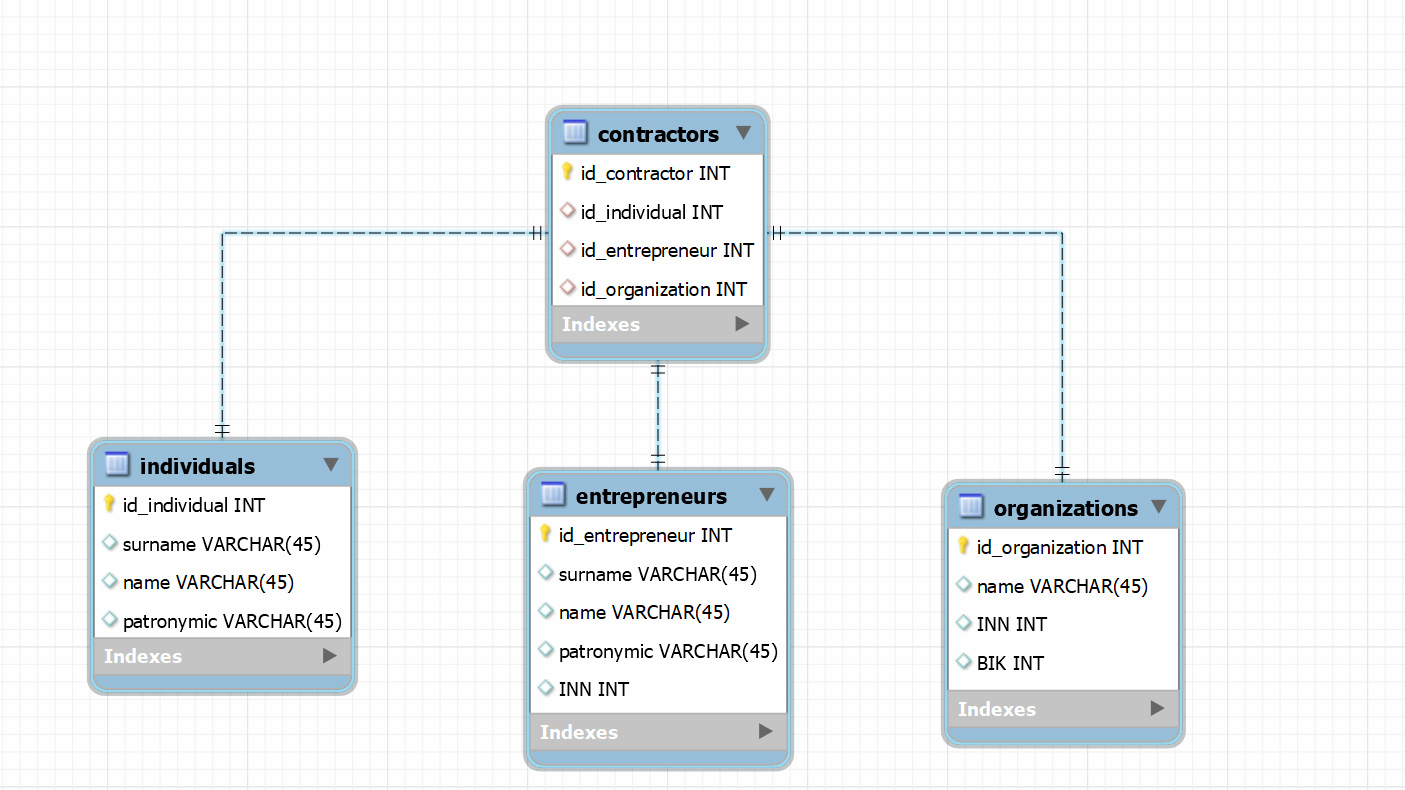
Это, по сути, наследование. Абстрактный класс-предок (поставщик) и конкретные классы-потомки (физлицо, ИП, организация). Наследование обычно выражается в структуре БД так: создаётся таблица "Поставщик", содержащая общие для всех классов поля и имеющая свой ключ.
Затем под каждый класс-потомок создаётся отдельная таблица, содержащая сведения, уникальные для этого класса. В этой таблице первичный ключ одновременно является внешним ключом, ссылающимся на таблицу "Поставщик". Иными словами, в таблице-потомке могут быть только записи с ключами, которые есть в таблице "Поставщик", а для каждой записи в "Поставщик" будет не более одной записи в таблице-потомке.
В таблице "Поставщик" также может быть поле, указывающее на конкретный тип поставщика (физлицо, ИП, организация), т.е. в какой таблице искать остальные данные. Наличие или отсутствие этого поля - вопрос вкуса. В принципе, если нам нужны сведения о конкретном типе поставщика, мы можем попытаться сделать INNER JOIN с нужной конкретной таблицей. Это отсеет все записи других типов.
Такой подход (без поля типа) позволяет избежать противоречий, когда запись находится в одной таблице-потомке, а поле указывает на другую. Но с другой стороны, если мы не знаем, какой конкретный тип у данного поставщика, нам придётся либо перебирать таблицы-потомки в рамках нескольких запросов к БД, либо делать LEFT JOIN со всеми таблицами-потомками, и смотреть, какие поля не будут NULL.
Слабая сторона такой схемы в том, что связь по внешнему ключу не запрещает существование записей в нескольких таблицах-потомках, ссылающихся на одну и ту же запись в "Поставщике". Это придётся контролировать отдельно, триггерами или хранимыми процедурами.





 Простой
Простой