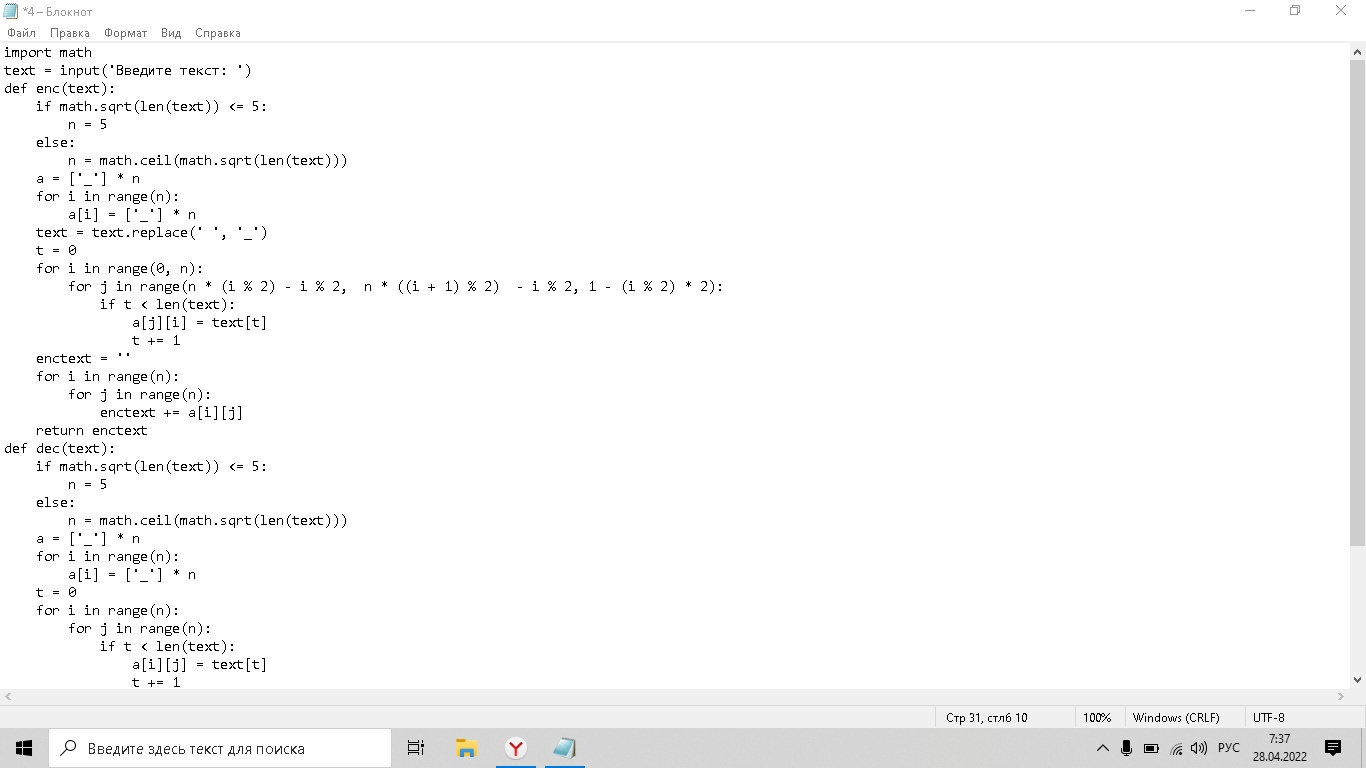
def enc(text):
#определяем размеры сетки. Если размер текста меньше 25и символов, то берем сетку 5х5.
# Иначе берем корень из размера текста и округляем вверх — это будет сторона сетки.
# можно в принципе упростить до n=max(5, math.ceil(math.sqrt(len(text))))
if math.sqrt(len(text)) <= 5:
n = 5
else:
n = math.ceil(math.sqrt(len(text)))
# создаем массив массивов символов '_' — это наша сетка
# можно упростить до a = [['_']*n]*n
a = ['_'] * n
for i in range(n):
a[i] = ['_'] * n
# в тексте меняем проблелы на подчеркивания
text = text.replace(' ', '_')
# и устанавливаем счетчик на ноль.
t = 0
# для каждого i от 0 до n
for i in range(0, n):
# для каждого j от (0 для четных i, n-1 для нечетных) до (n для четных i, -1 для нечетных) c шагом (1 для четных, -1 для нечетных)
# то есть для четных i берем j от 0 до n-1, а для нечетных — от n до -1.
# вероятно я обсчиталась и для нечетных должно быть от n-1 до 0. Но мне лень пересчитывать. Извините.
for j in range(n * (i % 2) - i % 2, n * ((i + 1) % 2) - i % 2, 1 - (i % 2) * 2):
# если текст еще не закончился
if t < len(text):
# берем следующую его букву (по счетчику, который мы там в начале установили в 0) и вставляем в сетку на место [j][i].
# То есть получается записываем текст в таблицу змейкой, сначала сверху вниз, потом снизу вверх, потом сверху вниз... пока текст не закончится
a[j][i] = text[t]
# прибавляем счетчик
t += 1
# создаем пустую строку (ой, это зря, ну да ладно)
enctext = ''
# прибавляем к пустой строке по порядку строки нашей таблицы.
# Это очень неэффективно т.к. при каждом добавлении по факту создается новая строчка.
# стоило написать что-то вроде ''.join(''.join(row) for row in a)
for i in range(n):
for j in range(n):
enctext += a[i][j]
# возвращаем получившуюся строчку
return enctext
def dec(text):
# определяем размер сетки как в первой функции
if math.sqrt(len(text)) <= 5:
n = 5
else:
n = math.ceil(math.sqrt(len(text)))
# создаем пустую сетку
a = ['_'] * n
for i in range(n):
a[i] = ['_'] * n
t = 0
# заполняем ее по порядку
for i in range(n):
for j in range(n):
if t < len(text):
a[i][j] = text[t]
t += 1
dectext = ''
# читаем змейкой сверху вниз, потом снизу вверх и тд
for i in range(0, n):
for j in range(n * (i % 2) - i % 2, n * ((i + 1) % 2) - i % 2, 1 - (i % 2) * 2):
dectext += a[j][i]
# меняем подчеркивания на проблеы и обрезаем лишнее.
dectext = dectext.replace('_', ' ').strip()
return dectext
# это просто тестовый код. Энкодим, печатаем, декодим, печатаем. Ничего сложного.
print("Шифрованный текст: " + enc(text))
print("Дешифрованный текст: " + dec(enc(text)))