Привет! Подскажите, плиз, что-то совсем запутался.
Примитивный фрейм данных.

Пытаюсь записать в новый стоблец схожесть текста в столбцах
a и
b
def similarity(s1, s2):
matcher = difflib.SequenceMatcher(None, s1, s2)
return matcher.ratio()
Пробовал так,
zz['sim1'] = similarity(zz['a'], zz['b'])
И так
zz['sim2'] = zz.apply(lambda row: similarity(zz['a'], zz['b']), axis=1)
Получается не то, что нужно. Как будто сравнивается весь стоблец сразу.
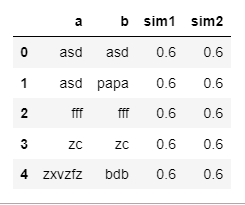
Нужно сравнить построчно и записать значение для каждой строки в новый столбец.
Буду благодарен любой помощи, наводки.
