Запускаем в разных клиентских окружений несколько аналитических расчетов на кластерах из поднимаемых на время облачных машин.
Хочется по-умному подойти к вопросу эффективности утилизации ресурсов.
В распределенных вычислениях очень важно, чтобы не было ситуации, когда одна машина делает работу, а все остальные ее ждут.
Задачу можно представить формально:
Сравнивая графики утилизации некоего ресурса (к примеру, CPU) каждой из кластерных машин, можно вывести коэффициент равномерности загрузки. Если графики утилизации у всех машин примерно совпадают, можно сделать предположение, что такой кластер более эффективно распределяет нагрузку, по сравнению с ситуацией, когда графики утилизации совпадают хуже.
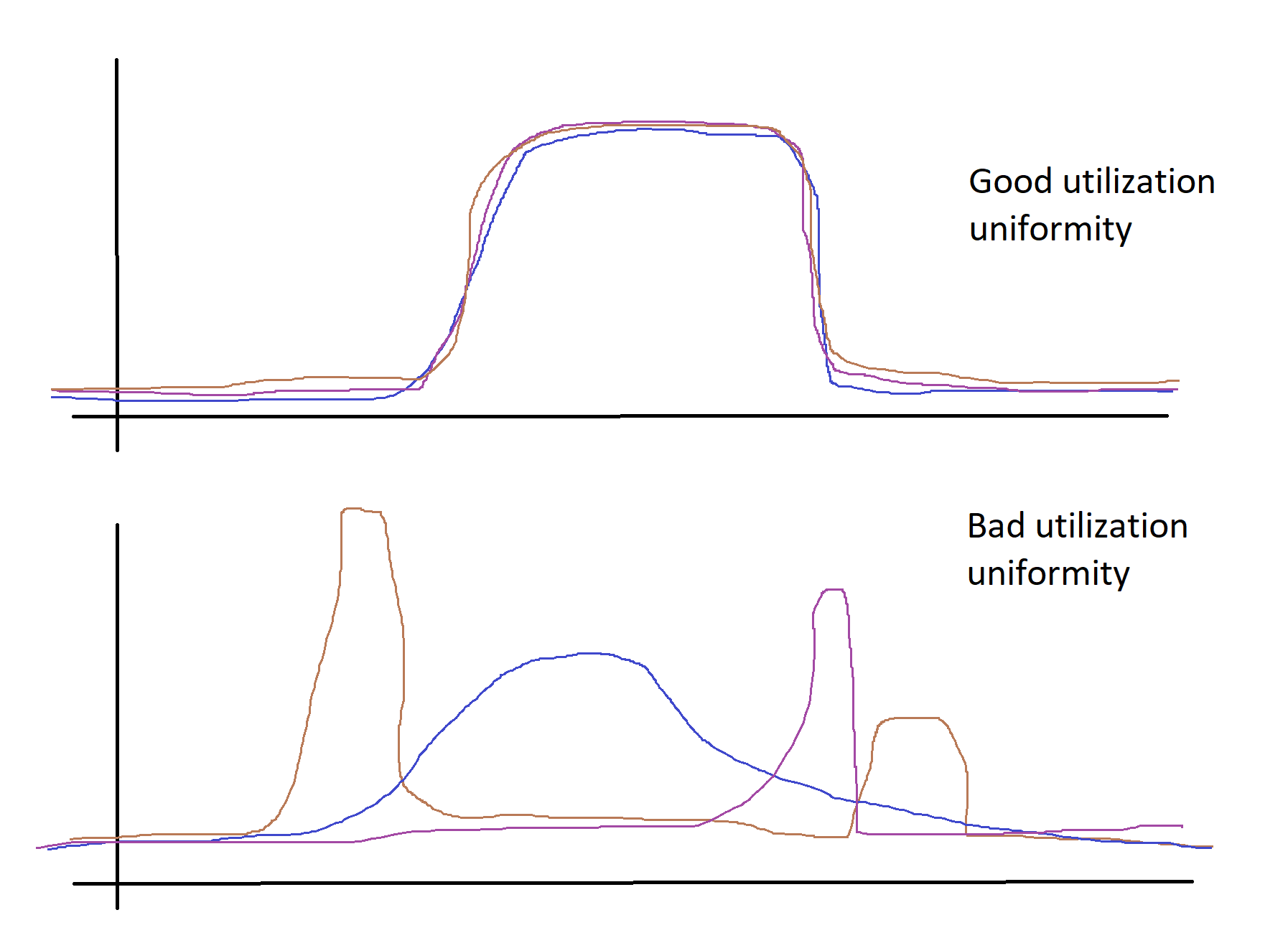
Получив для каждого запуска расчета такой индекс эффективности, можно значительно улучшить понимание того, какой расчет стоит улучшать в первую очередь.
Перед тем, как начать самим придумывать такую библиотеку, хотелось бы узнать, есть ли в природе проекты, решающие такую задачу? Идея не выглядит как что-то экстраординарное.




 Средний
Средний
 Средний
Средний






