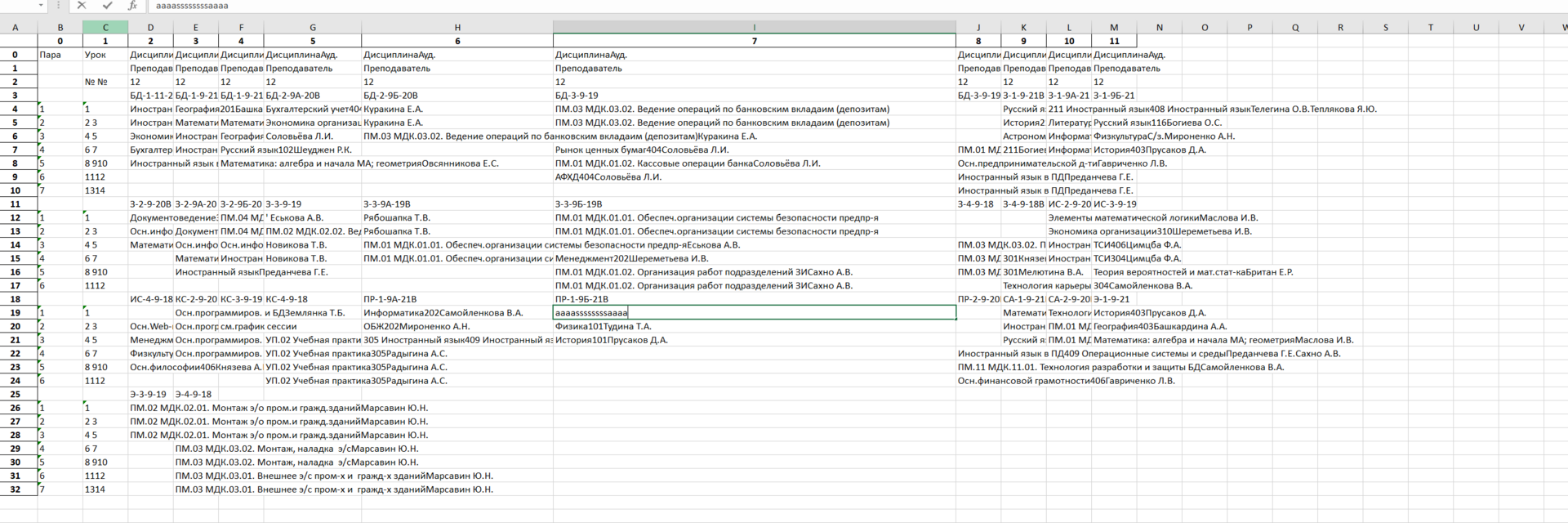
Имеется расписание занятий по группам, которое высылается каждый день в pdf файле в виде таблицы.
Нужно с помощью python извлечь занятия и кабинеты определенной группы. Не могу понять как это реализовать.
Файл выглядит так:

Результат может быть в виде текста, или в виде обрезанного фото с занятиями определенной группы.
Пробовал различные библиотеки, такие как: tabula, PyPDF2, camelot. Всё что у меня получилось, это вот:

Также такой вариант:
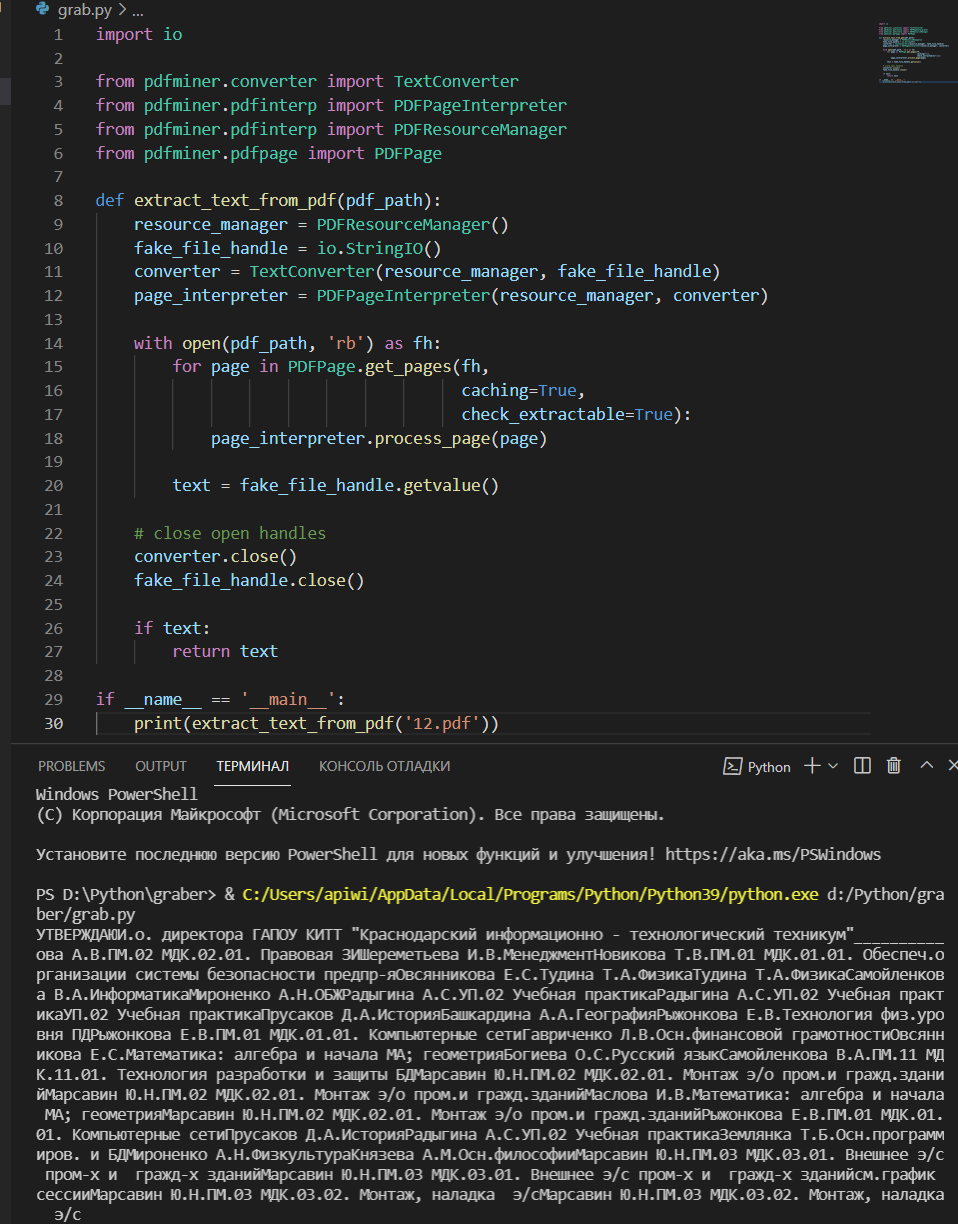
Я понимаю, что возможно вы мне скажите идти на фриланс биржу, но нет, мне нужно чтоб меня натолкнули на идею выполнения задачи. Спасибо.