Отвечу на что смогу.
> Как посчитать нейросеть для тупого запоминания выборки?
> Почему обучая нейросеть она может менять свой процент правильности?
> Почему при увеличении слоев сеть порой тупеет.
Это называется переобучение. Если очень наглядно, то это можно представить так:

Слева - недостаточно сложная сеть. Она не может приспособиться к сложности данных, и даёт только грубое подобие той закономерности, которую мы моделируем.
Справа - чрезмерно сложная сеть. Она очень хорошо вписывается в обучающую выборку (точки на графики), но если ей дать промежуточные точки (т.е. те. которых не было в обучаяющей выборке), она будет давать сильно отличающиеся от реальных ответы. Это и есть "сеть зазубрила выборку" (подразумевается "вместо того, чтобы понять её закономерности").
Твоя задача как архитектора сети - выбрать такие гиперпараметры (это то, что ты выбираешь до обучения - число слоёв, размер слоёв, скорость обучения, функция активации и т.д.), чтобы сеть не переобучалась.
Собственно, на графике ошибки сети это как раз выглядит так:
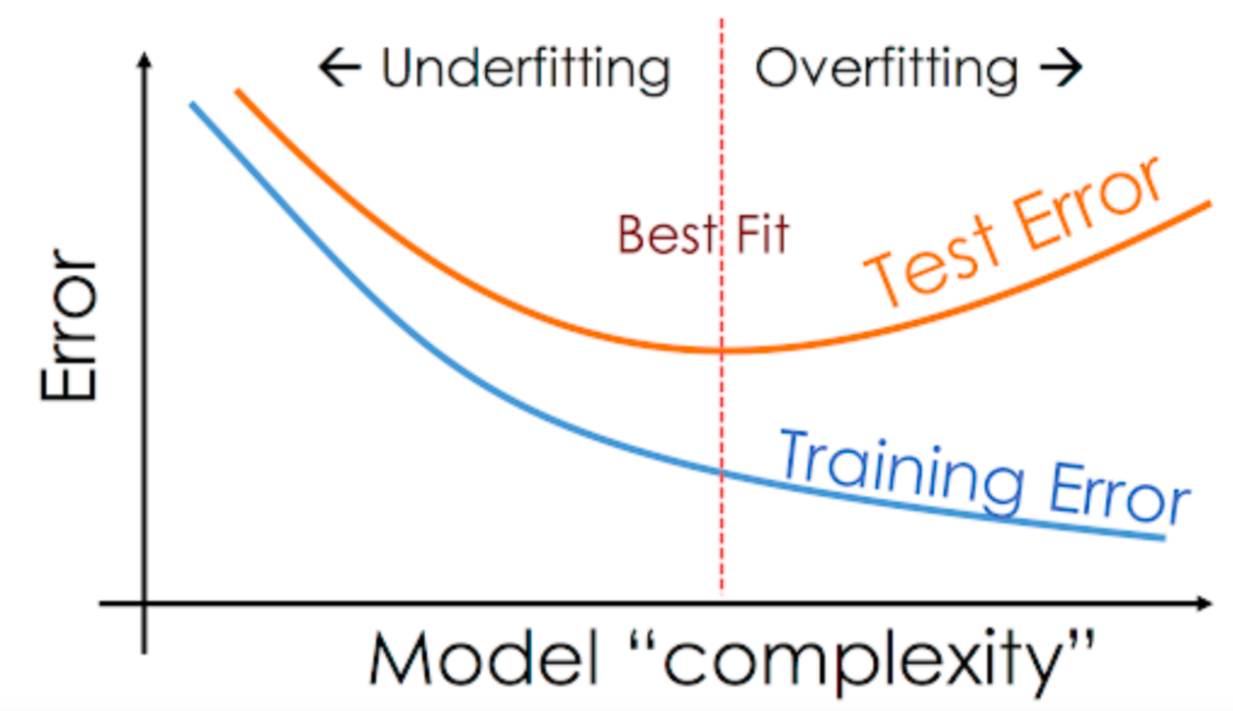
Синяя кривая - ошибка на обучающей выборке. Желтая - на контрольной. По оси X - сложность сети.
Тогда твоё поведение объясняется так. Сложная сеть сначала быстро приспосабливается к выборке (быстро падает ошибка на обоих выборках), а потом начинает зазубривать обучающую выборку (и набирать ошибку на контрольной, так как перестаёт понимать закономерности). Если ты это наблюдаешь - сеть слишком сложная.


 Простой
Простой
 Простой
Простой
 Простой
Простой

