У меня браузер хром вообще перестал работать, а мозила жестко тормозит, если открыто несколько вкладок
useradd: user 'arch' already exists
userdel -r имя_пользователя-r удалит также и домашнюю директории указанного пользователяuseradd group 'users' does not exist useradd the GROUP configuration in /etc/default/useradd will be ignored
usersgroupadd группаuseradd по умолчанию создаётся группа, название которой совпадает с именем пользователя и в которую затем автоматом и добавляется создаваемый пользователь у которого она будет основная. Естественно с помощью ключей поведение можно изменить. В других дистрах в основную группу пользователя часто ставят группу users
fdisk(диалоговый) is a dialog-driven program for creation and manipulation of partition tables.(man)cfdisk(псевдографический) is a curses-based program for partitioning any block device.(man)sfdisk(скрипто-ориентированный) is a script-oriented tool for partitioning any block device.(man)fdisk, cfdisk и sfdisk это связные утилиты входящие в util-linuxsfdisk который хорошо подходит для указания не интерактивных команд работы с разделами:echo -e "label:gpt\nstart=1M" | sudo sfdisk /dev/sdb$HOME/.zshrc такие строки:source /usr/share/fzf/key-bindings.zsh
source /usr/share/fzf/completion.zshpacman -Qqs | grep ghpacman -R $(pacman -Qqs | grep gh)pacman -Rsc $(pacman -Qqs | grep gh)pacman -Rdd $(pacman -Qqs | grep gh)
#!/usr/bin/env bash
#set -o xtrace
set -o nounset
set -o errexit
set -o pipefail
URL="$1"
DIR="$PWD"
FILENAME=$(yt-dlp --print filename -o "%(title)s" "$URL")
FILE_JSON="$DIR/$FILENAME".json
FILE_COMMENTS="$DIR/$(date +"%y%m%d") $FILENAME".txt
yt-dlp --write-comments --dump-single-json "$URL" > "$FILE_JSON"
echo -e "$URL\n" > "$FILE_COMMENTS"
cat "$FILE_JSON" | jq -r '.title' >> "$FILE_COMMENTS"
echo "--------------------------------------------------" >> "$FILE_COMMENTS"
cat "$FILE_JSON" | jq -r '"Просмотров: \(.view_count) Лайков: \(.like_count) Комментариев: \(.comment_count)"' >> "$FILE_COMMENTS"
echo "--------------------------------------------------" >> "$FILE_COMMENTS"
cat "$FILE_JSON" | jq -r '.comments[] | if .parent == "root" then "\n+\(.like_count) \(.author) >>> \(.text)" else "\t+\(.like_count) \(.author) >>> \(.text)" end' >> "$FILE_COMMENTS"Есть команда показывающая кол-во подключенных ЮСБ к серверу и их наименование
lsusb is a utility for displaying information about USB buses in the system and the devices connected to them.
RED='\033[0;31m'
GREEN='\033[0;32m'
NORMAL='\033[0m'
OK="${GREEN}OK${NORMAL}"
NO="${RED}NO${NORMAL}"
lsusb |awk -v ok="$OK" -v no="$NO" '{print $3" "$4" - "$7" "$8" "$9" "no}'$ du -sb * |awk '{cmd="stat -c %z "$2" |cut -d\" \" -f1";cmd |getline z;close(cmd);print z" "$1}' |awk '{sum[$1]+=$2}END{for(i in sum)print i,sum[i]}' |sort |numfmt --to=iec --field 2 --padding=10
2022-01-21 13M
2022-11-02 17G
2022-12-13 4,7G
2023-01-15 388M
2023-03-06 1,6G
2023-04-01 1,6G
2023-04-03 2,2G
2023-04-04 13G
2023-04-11 7,6Glsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/sda
echo ", +" | sudo sfdisk --no-reread -N 4 /dev/sda
echo ", +" | sudo sfdisk --no-reread -N 5 /dev/sda
sudo partx --update /dev/sda
lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/sda
sudo resize2fs -f /dev/sda5
lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/sda$ truncate -s 1G test.img
$ echo -e "label:dos\nsize=100M,bootable,type=L\nsize=200M,type=L\nsize=300M,type=L\ntype=Ex\nsize=+" | sfdisk test.img
Проверяется, чтобы сейчас никто не использовал этот диск... ОК
Диск test.img: 1 GiB, 1073741824 байт, 2097152 секторов
Единицы: секторов по 1 * 512 = 512 байт
Размер сектора (логический/физический): 512 байт / 512 байт
Размер I/O (минимальный/оптимальный): 512 байт / 512 байт
>>> Заголовок скрипта принят.
>>> Создана новая метка DOS с идентификатором 0xa605c035.
test.img1: Создан новый раздел 1 с типом 'Linux' и размером 100 MiB.
test.img2: Создан новый раздел 2 с типом 'Linux' и размером 200 MiB.
test.img3: Создан новый раздел 3 с типом 'Linux' и размером 300 MiB.
test.img4: Создан новый раздел 4 с типом 'Extended' и размером 423 MiB.
test.img5: Создан новый раздел 5 с типом 'Linux' и размером 422 MiB.
test.img6: Done.
Новая ситуация:
Тип метки диска: dos
Идентификатор диска: 0xa605c035
Устр-во Загрузочный начало Конец Секторы Размер Идентификатор Тип
test.img1 * 2048 206847 204800 100M 83 Linux
test.img2 206848 616447 409600 200M 83 Linux
test.img3 616448 1230847 614400 300M 83 Linux
test.img4 1230848 2097151 866304 423M 5 Расширенный
test.img5 1232896 2097151 864256 422M 83 Linux
Таблица разделов была изменена
Синхронизируются диски.
$ losetup --partscan --show --find test.img
/dev/loop0
$ lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/loop0
NAME TYPE FSTYPE SIZE FSSIZE MOUNTPOINT
/dev/loop0 loop 1G
├─/dev/loop0p1 part 100M
├─/dev/loop0p2 part 200M
├─/dev/loop0p3 part 300M
├─/dev/loop0p4 part 1K
└─/dev/loop0p5 part 422M
$ mkfs.ext4 /dev/loop0p5
$ mkdir /tmp/mnt
$ sudo mount /dev/loop0p5 /tmp/mnt
$ lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/loop0
NAME TYPE FSTYPE SIZE FSSIZE MOUNTPOINT
/dev/loop0 loop 1G
├─/dev/loop0p1 part 100M
├─/dev/loop0p2 part 200M
├─/dev/loop0p3 part 300M
├─/dev/loop0p4 part 1K
└─/dev/loop0p5 part ext4 422M 385,2M /tmp/mnt
$ truncate -s +1G test.img
$ sudo losetup --verbose --set-capacity /dev/loop0
$ lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/loop0
NAME TYPE FSTYPE SIZE FSSIZE MOUNTPOINT
/dev/loop0 loop 2G
├─/dev/loop0p1 part 100M
├─/dev/loop0p2 part 200M
├─/dev/loop0p3 part 300M
├─/dev/loop0p4 part 1K
└─/dev/loop0p5 part ext4 422M 385,2M /tmp/mnt
$ echo ", +" | sudo sfdisk --no-reread -N 4 /dev/loop0
$ sfdisk --dump /tmp/test.img
label: dos
label-id: 0xa605c035
device: /tmp/test.img
unit: sectors
sector-size: 512
/tmp/test.img1 : start= 2048, size= 204800, type=83, bootable
/tmp/test.img2 : start= 206848, size= 409600, type=83
/tmp/test.img3 : start= 616448, size= 614400, type=83
/tmp/test.img4 : start= 1230848, size= 2963456, type=5
/tmp/test.img5 : start= 1232896, size= 864256, type=83
$ echo ", +" | sudo sfdisk --no-reread -N 5 /dev/loop0
$ sfdisk --dump /tmp/test.img
label: dos
label-id: 0xa605c035
device: /tmp/test.img
unit: sectors
sector-size: 512
/tmp/test.img1 : start= 2048, size= 204800, type=83, bootable
/tmp/test.img2 : start= 206848, size= 409600, type=83
/tmp/test.img3 : start= 616448, size= 614400, type=83
/tmp/test.img4 : start= 1230848, size= 2963456, type=5
/tmp/test.img5 : start= 1232896, size= 2961408, type=83
$ sudo partx --update /dev/loop0
$ lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/loop0
NAME TYPE FSTYPE SIZE FSSIZE MOUNTPOINT
/dev/loop0 loop 2G
├─/dev/loop0p1 part 100M
├─/dev/loop0p2 part 200M
├─/dev/loop0p3 part 300M
├─/dev/loop0p4 part 1K
└─/dev/loop0p5 part ext4 1,4G 385,2M /tmp/mnt
$ sudo resize2fs /dev/loop0p5
$ lsblk -p -o NAME,TYPE,FSTYPE,SIZE,FSSIZE,MOUNTPOINT /dev/loop0
NAME TYPE FSTYPE SIZE FSSIZE MOUNTPOINT
/dev/loop0 loop 2G
├─/dev/loop0p1 part 100M
├─/dev/loop0p2 part 200M
├─/dev/loop0p3 part 300M
├─/dev/loop0p4 part 1K
└─/dev/loop0p5 part ext4 1,4G 1,3G /tmp/mnt
$ sudo umount /tmp/mnt
$ losetup -d /dev/loop0yay -S pscircle$HOME/.local/bin/background#!/usr/bin/env bash
PICTURE_PATH=/tmp/pscircle.png
TIME_UPDATE=5 # ставить >= 2
# борьба с дублями программы
PID_PATH=/tmp/background.pid
[[ -e $PID_PATH ]] && kill $(cat $PID_PATH)
echo $$ > $PID_PATH
[[ -n "$(pgrep swaybg)" ]] && pkill swaybg
while :; do
pscircle --output=$PICTURE_PATH \
--max-children=50 \
--output-width=1920 \
--output-height=1080 \
--tree-radius-increment=150 \
--dot-radius=3 \
--link-width=1.3 \
--tree-font-size=13 \
--toplists-font-size=20 \
--tree-center=-300:0 \
--cpulist-center=600.0:-120.0 \
--memlist-center=600.0:120.0
swaybg --image $PICTURE_PATH \
--mode center \
--color "#000000" \
--output "*" &
# время на установку нового изображения перед тем как убрать старое
# убирает мерцание при смене обоев
sleep 1
[[ -n $pid ]] && kill $pid
pid=$(pgrep swaybg)
sleep $[TIME_UPDATE-1]
done#!/usr/bin/env bash
PICTURE_PATH=/tmp/pscircle.png
TIME_UPDATE=5
# борьба с дублями программы
PID_PATH=/tmp/background.pid
[[ -e $PID_PATH ]] && kill $(cat $PID_PATH)
echo $$ > $PID_PATH
[[ -n "$(pgrep swaybg)" ]] && pkill swaybg
while :; do
pscircle --output=$PICTURE_PATH
swaymsg "output * background $PICTURE_PATH fill #000000"
sleep $TIME_UPDATE
donechmod +x $HOME/.local/bin/background$HOME/.config/sway/config добавляем строчкуexec_always $HOME/.local/bin/backgroundbindsym $mod+Shift+c reload
chmod +x Total_LBAs_Written#!/usr/bin/env bash
##############################################################################################################
# Описание
#
# Определение количества записанных данных на диск за всё время его работы исходя из RAW показателей smartctl
# Грубо говоря, это перевод значения показателя Total_LBAs_Written в человеко понятный вид за счет сравнения его
# показателей до и после записи тестового файла на выбранный диск.
#
#
# Условие работы
#
# Для работы программы в системе должны присутствовать следующие утилиты:
# smartctl
# fzf
#
#
# Использование
#
# Примеры запуска программы:
# $ sudo Total_LBAs_Written
# $ sudo Total_LBAs_Written 2G
# $ sudo Total_LBAs_Written 100М
#
# далее в меню выберите нужный диск и нажмите Enter
# по умолчанию тестовый файл берётся в 1 гиг, но можно указать и своё значения передав его программе первым параметром.
# В меню будут отображаться тока те диски которые соответствуют критериям:
# - несъёмный
# - примонтирован в системе
# - не быть в режиме только для чтения (для возможности записи на него временных тестовых данных)
# - иметь достаточно места для записи тестового файла
#
#
# Пример вывода программы
#
# $ sudo Total_LBAs_Written 100M
# Total_LBAs_Written (1) = 5860217375
# Total_LBAs_Written (2) = 5860422239 ~ 2999598811739 bytes = 2,8T
# (2) - (1) = 204864 ~ 104857600 bytes = 100M (test file size)
# ==============================================================================
# Итого на диск /dev/sda было всего записанно порядка 2,8T
#
##############################################################################################################
# set -o xtrace
set -o nounset
set -o errexit
set -o pipefail
TESTFILE_SIZE=${1:-1G}
TESTFILE_SIZE_BYTES=$(numfmt --from=iec $TESTFILE_SIZE)
disk_partitions(){
lsblk -plo PKNAME,NAME,MOUNTPOINT $(lsblk -rbpo "PATH,RM,RO,FSAVAIL" |awk -v size=$TESTFILE_SIZE_BYTES '$2==0&&$3==0&&$4>size{print $1}')
}
export TESTFILE_SIZE_BYTES
export -f disk_partitions
SELECTED_PARTITION=$(disk_partitions \
|fzf --bind 'ctrl-r:reload(bash -c 'disk_partitions')' \
--header $'Ctrl+c\t- выйти\nCtrl+r\t- обновить\nEnter\t- выбрать\n\n' \
--header-lines=1 \
--layout=reverse \
|awk '{print $2}' )
DISK=$(lsblk -npo PKNAME $SELECTED_PARTITION)
TLW1=$(smartctl -a $DISK | awk '/Total_LBAs_Written/{print $NF}')
[[ -z $TLW1 ]] && echo "Параметр Total_LBAs_Written на текущем диске $DISK не найден !!!" && exit 1
TESTFILE_PATH=$(lsblk -no MOUNTPOINTS $SELECTED_PARTITION)/testfile
sync -f $SELECTED_PARTITION
dd if=/dev/zero of=$TESTFILE_PATH bs=$TESTFILE_SIZE_BYTES count=1 status=none
sync -d $TESTFILE_PATH
rm $TESTFILE_PATH
TLW2=$(smartctl -a $DISK | awk '/Total_LBAs_Written/{print $NF}')
echo "Total_LBAs_Written (1) = "$TLW1
TLW2_SIZE=$(echo "$TLW2*$TESTFILE_SIZE_BYTES/($TLW2-$TLW1)"|bc)
echo "Total_LBAs_Written (2) = $TLW2 ~ $TLW2_SIZE bytes = "$(numfmt --to=iec $TLW2_SIZE)
echo " (2) - (1) = $[TLW2-TLW1] ~ $TESTFILE_SIZE_BYTES bytes = "$(numfmt --to=iec $TESTFILE_SIZE_BYTES)" (test file size)"
echo ==============================================================================
echo "Итого на диск $DISK за всё время его работы было записанно порядка $(numfmt --to=iec $TLW2_SIZE)"
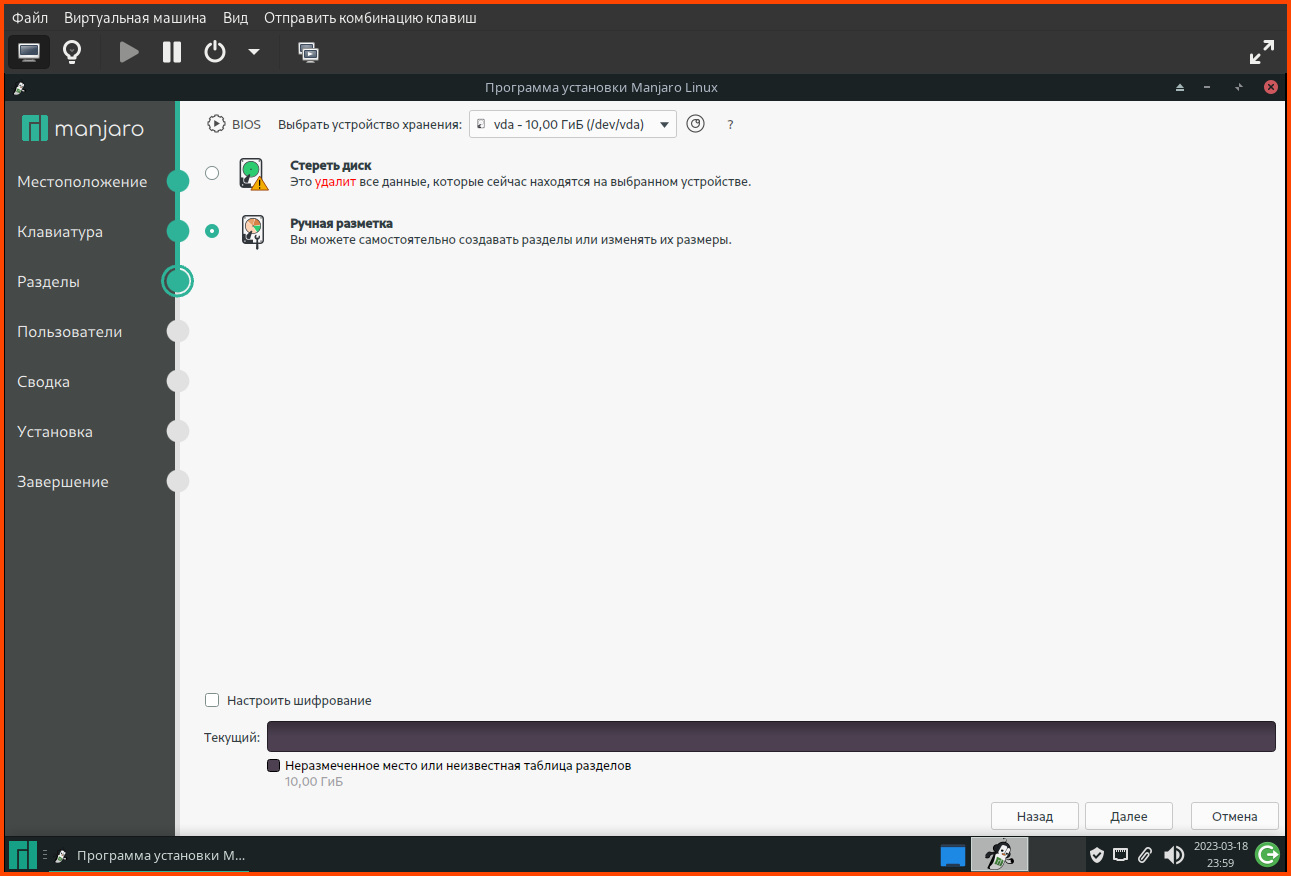
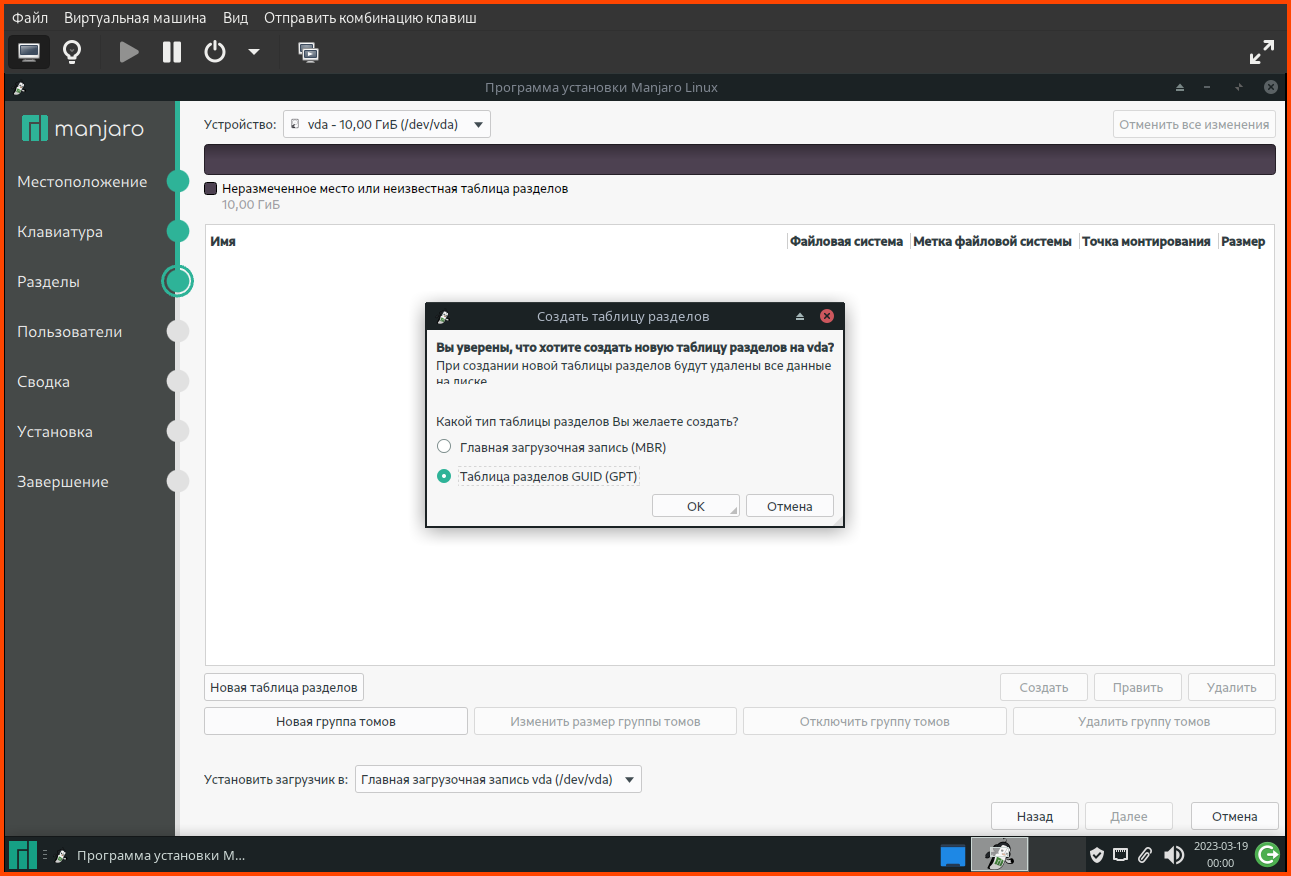
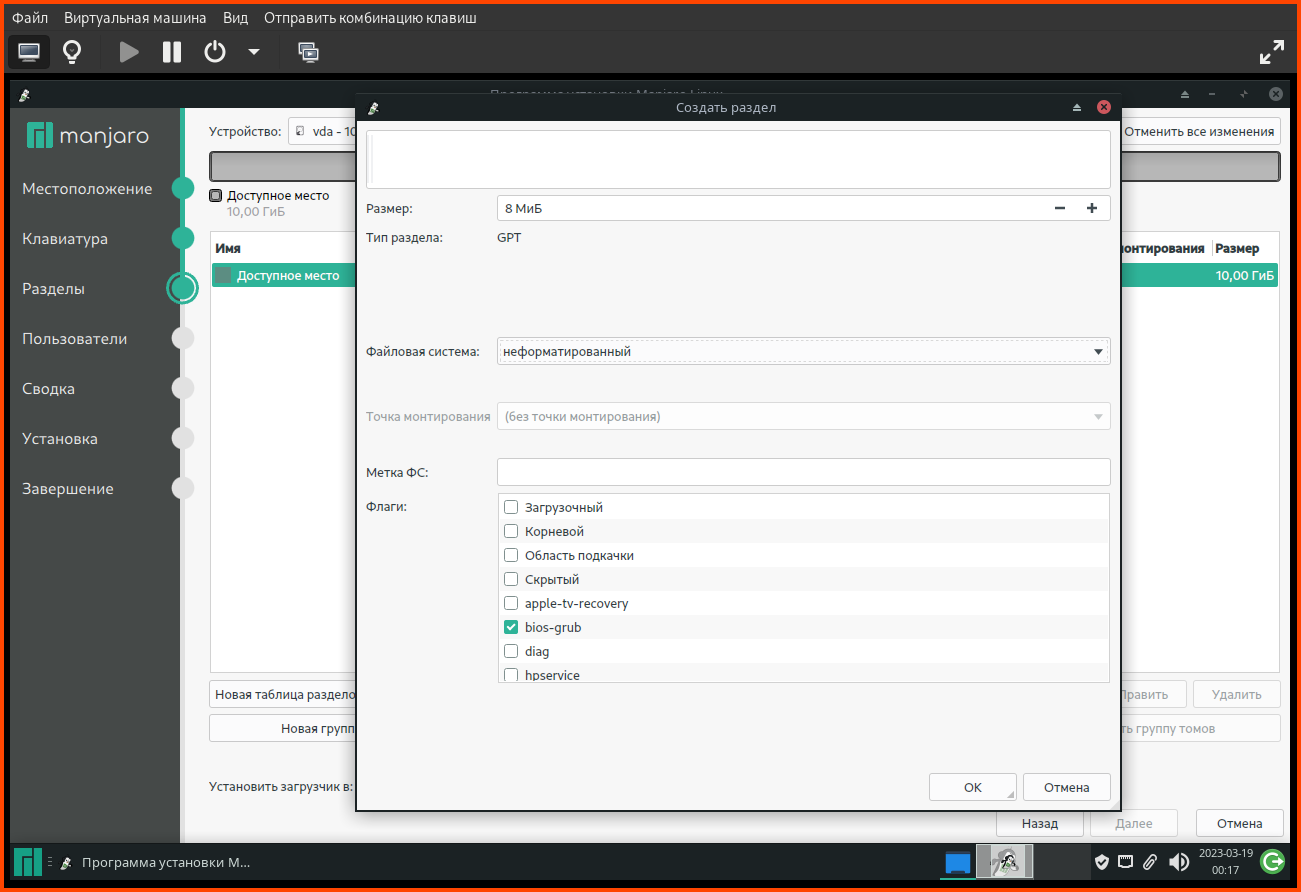
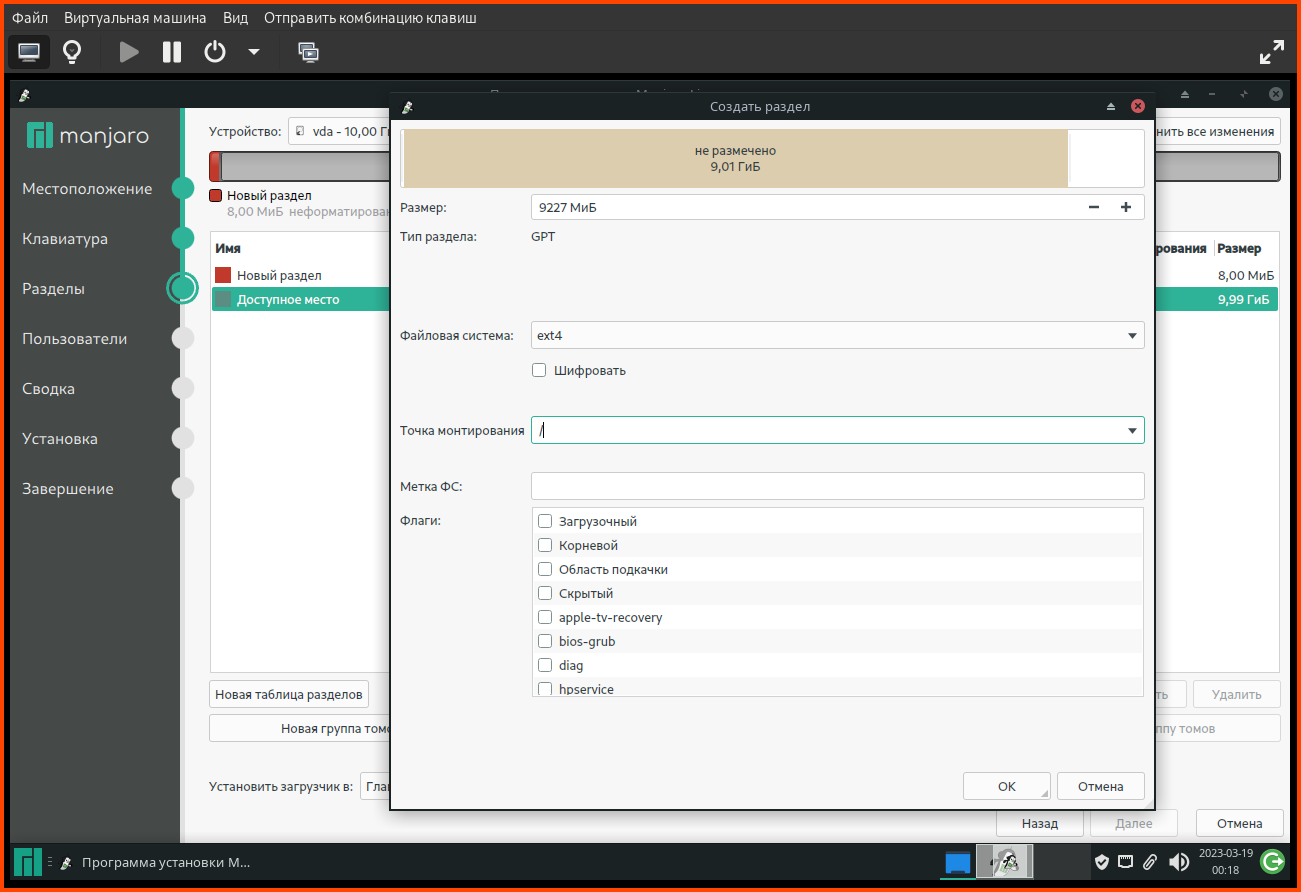
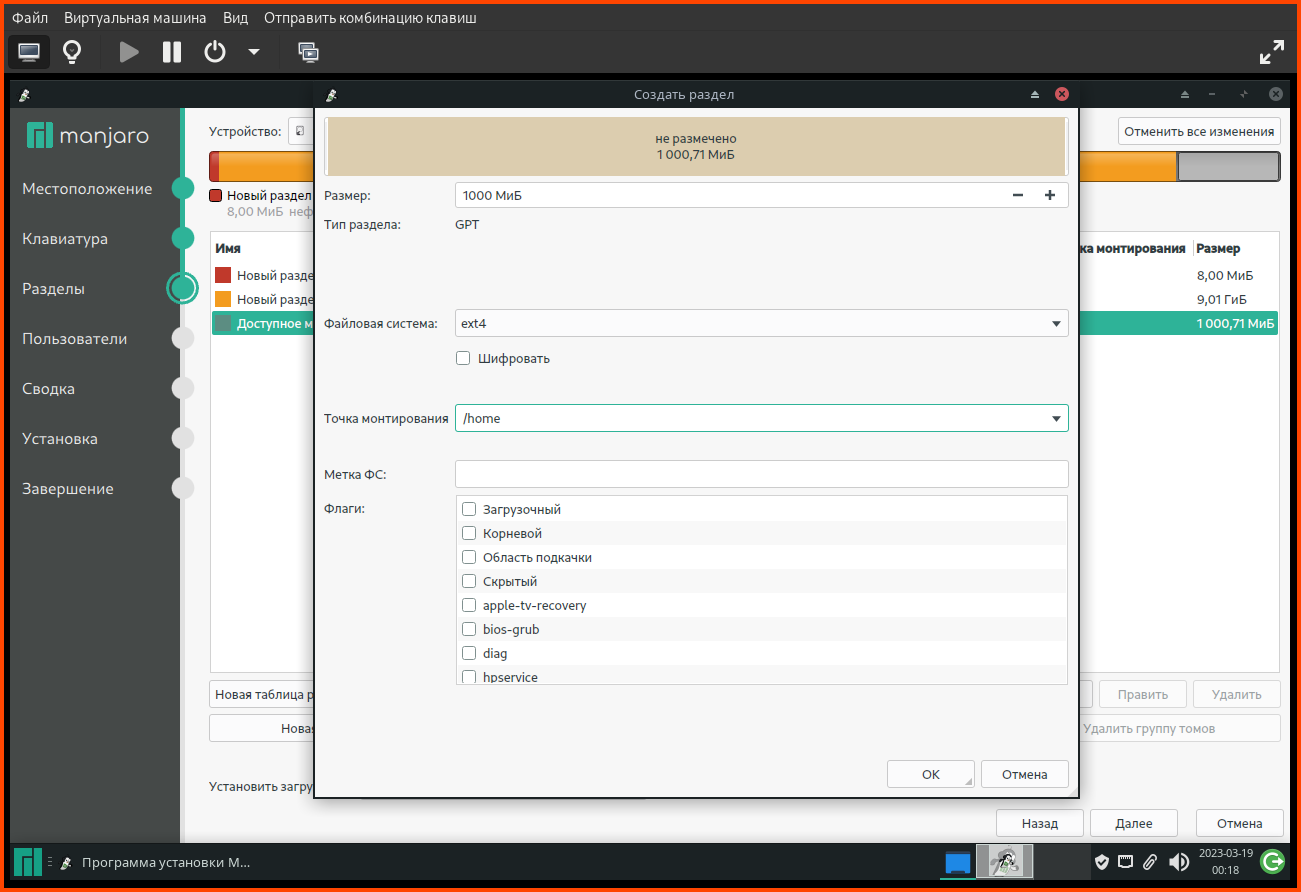
exitpaste file1 file2paste <(hostnamectl) <(hostnamectl)hostnamectl |awk '{print $0";"}'paste <(hostnamectl |awk '{print $0";"}') <(hostnamectl)paste <(hostnamectl |awk '{print $0";"}') <(hostnamectl) | column -t -s';'paste <(hostnamectl |awk '{print $0";"}') <(hostnamectl) | csview -H -d';'paste <(hostnamectl) <(hostnamectl) | csview -H --tsvДа, я немного не правильно выразился, хочу из одного ссд сделать грубо говоря два (на виндовс-языке: разбить на два тома), и в один "том" записать /root, /swap и т.д, а во второй /home, и было бы неплохо еще и /usr.
$ pacman -v
...
DB Path : /var/lib/pacman/telegram-desktop
firefox
chromium
emacssudo pacman -S $(<pacman.list)yay -S $(<pacman.list)sudo pacman -S $(curl -s ...)