Всем спасибо за помощь и советы!
Было сделано сразу две манипуляции способствующие решению проблемы. Какая из них решила проблему точно уже не скажу.
У Битрикс есть таблица с купонами скидок каталога, в ней у нас было 300 тыс. купонов. Так как изменить запрос нет возможности из-за его системности и обновления Битрикс все затрут, то были проведены тесты с данными. Удаление из таблицы 200 тыс. старых купонов позволило ускорить медленный запрос с ~1.3 сек. до 0.01 сек. В таблице осталось 60 тыс. купонов.
Будем дорабатывать систему автоматической очистки купонов и писать обращение в Битрикс с просьбой оптимизации запроса. Хотя медленный запрос по данным мониторинга и отрабатывал ~3.7 раз в секунду, но это не мешало ему душить процессор.
Второе мероприятие это переход с mariadb (10.1, 10.3 - обе версии тестировались по несколько дней) на percona 8. Предположение пало на проблему базы данных с нашим набором данных и запросами, была мысль, а вдруг в перконе знаю и устранили ошибку.
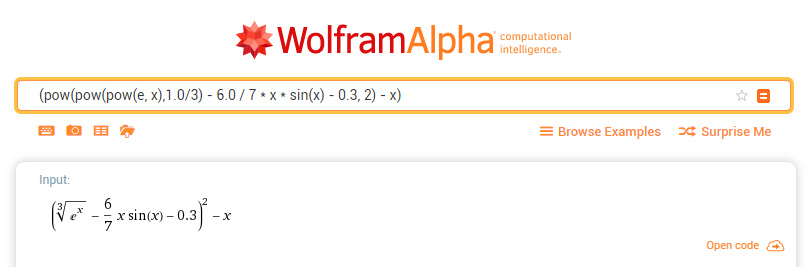
Я все же полагаю, что ключевой фактор тут был указанный
Vitaly Karasik на медленный запрос.
Видимо на наших данных этот запрос вызывал блокировки и высокую нагрузку на CPU из за повышения значений метрик RW Locks S OS Waits, RW Locks X OS Waits, RW Locks S Spin Rounds, RW Locks X Spin Rounds. Купонов становилось больше и в какой-то момент времени их кол. стало критичным для запроса.
Плавающий LA независящий от количества запросов к базе данных оказался влиянием вызова заданий по крону на выгрузку в яндекс маркет каталогов. Буду привязывать отображение заданий агентов Бирикс (крон задачи) на графиках, чтобы в будущем более явно строить связи нагрузки и работу приложения.
UPDATE 09.08.2019
Базу данных вернул на mariadb 10.3. Выяснился еще один запрос повышающий нагрузку на CPU. У нас около 1 млн. сессий в база данных. Так вот Битрикс в методе Sale\Fuser::getIdByUserId($ID) получения одной записи не выставляет лимит и еще и сортирует всю выборку. Если передается FALSE, то он сортировал в нашем случае около 1 млн. записей + добавлял туда каждый раз еще 1 запись. Обращение в Битрикс отправлено, они его приняли и судя по всему скоро будет выпущено обновление.
Кому нужно решение сейчас - измените метод прямо в ядре Sale\Fuser::getIdByUserId таким образом.
$res = FuserTable::getList(array(
'filter' => array(
'USER_ID' => $userId
),
'select' => array(
'ID'
),
'limit' => 1, // Добавить лимит
// 'order' => array('ID' => "DESC") // Убрать эту сортировку
));