itsLegend, рекомендую развернуть вопрос, отредактируйте и добавьте туда очевидные для вас, но неизвестные отвечающим сведения: требования к надежности, скорости, способу взаимодействия, типы данных, объёмы; вообще, прям обязательно mysql? Для таких задач есть и относительно простенькие, типа sqlite3, и навороченные и специфичные, типа redis.
:)) это же смотря для чего… одно - хранить временно некритичные данные, создавая структуру каждый раз при перезагрузке; другое - хранить вечно регулярно пополняющиеся громадные массивы из множества таблиц, с многоэтажными select-ами и прочими join-ами и union-ами (тьфу-тьфу-тьфу).
Ну и, если ты делаешь это надолго, то система на готовых сервисах легче расширяется, обновляется и поддерживается, а свой велосипед ты запаришься поддерживать годами.
3Create, это всё можно сделать и на чистом Python с библиотеками разнообразными, но на nodered визуально лепится и относительно просто настраивается.
Хотя сначала надо понять кое-какие нюансы, но потом довольно просто - многие велосипеды уже есть готовые, надо только полученные данные правильно распарсить и преобразовать в другие форматы, нужные для других модулей.
3Create, блин… это не чистый Python, это отдельные сервисы надо поднимать:
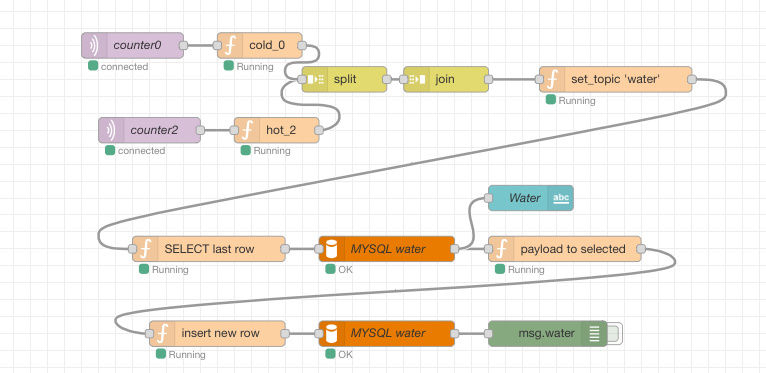
у меня поднят mariadb, mosquito, nodered и в nodered вот такая фигнюшка:
Там в некоторых элементах код Python, в некоторых всякие готовые функции взаимодействия с датчиками, базой и т.п., ну и есть модуль (бирюзовый), который отображает график.
Вот такими могут быть графики:
Я, например, собираю данные с датчиков в sql посредством mqtt, а графики в локальной сети в браузере рисую посредством доп.модулей к node red. В node red можно и на Python функции писать, хотя нативно там js.
Если данные хранить вечно не надо, можно sqlite3 в памяти даже сделать. А вот с отображением - сильно зависит, где именно хочешь отображать - у себя на экране локальном, в локальной сети на страничке в браузере, в инете в браузере, а может в jpg?
Давай уточним вопрос: правильно ли я понял, что надо из списка оставить те элементы, которые начинаются на три первых символа такие, как в начальном элементе списка?
Skriptgr, в интернете вот это: «НУЖНО БОЛЬШЕ ЗОЛОТА» - т.е. написание сообщений капс-ом - считается криком.
Ну, типа сидят спокойно люди в клубе, почитывают вопросы, пишут ответы. Всё тихо, спокойно. И тут вбегает кто-то и кричит: «РЕШИТЕ СРОЧНО МОЙ ВОПРОС!!!111»
Ну вы понимаете, да?
toarugakusei, я вас и не обвиняю. В конце концов, на то есть модераторы.
Но и превращать сервис вопросов и ответов в аналог github тоже не правильно. Выглядит так, будто вы ведёте разработку прямо тут.
Полагаю, вы взвалили на себя слишком сложную задачу, не владея необходимыми навыками и знаниями. Оттого и куча однотипных вопросов. Может, не ломиться в закрытые двери, а потратить время на то, чтобы добыть ключи?