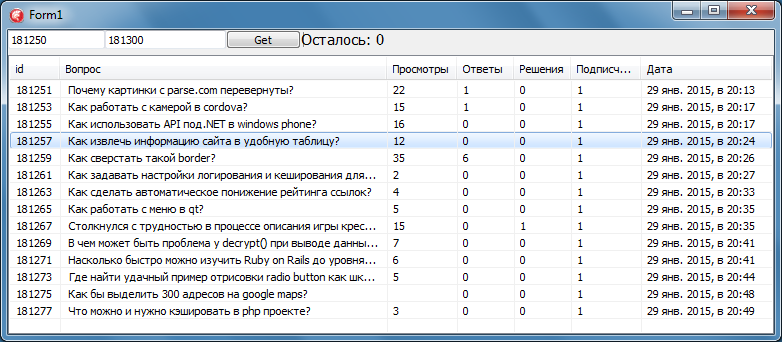
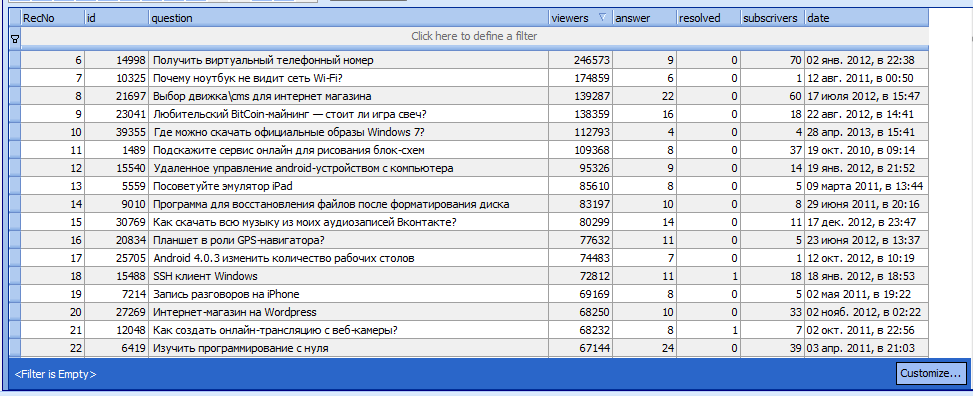
import requests
headers = {'Content-Type':'application/json;charset=utf-8'}
url = 'https://www.vtb.ru/api/sitecore/coinsapi/filter'
data = '{"query":"","newCollection":false,"Discounted":false,"GiftBox":false,"Order":"priceAsc","SearchGroups":false,"CoinList":"all","Favorites":[],"Groups":["8e67bb77202c40fa8ae0258d5bcb66f8","087e7eca08724e88aa1fbd0ebb0ebf70"],"Series":[],"Themes":[],"Metals":[],"PriceMin":"","PriceMax":"","Page":1,"ResultsOnPage":16}'
response = requests.post(url,data=data,headers=headers)https://www.avito.ru/items/phone/id_объявленияс параметрами:
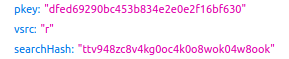
import requests
import base64
params = { 'pkey':'dfed69290bc453b834e2e0e2f16bf630', # Осталось узнать, как генерируется это значение!
'vsrc':'r',
'searchHash':'ttv948zc8v4kg0oc4k0o8wok04w8ook' # И это тоже!
}
url = 'https://www.avito.ru/items/phone/1315030387'
response = requests.get(url,params=params)
with open("imageToSave.png", "wb") as fh:
fh.write(base64.decodebytes(response.text[34:-2].encode()))
Есть ли например такая возможность как один раз открыть сайт и постоянно считывать с него информацию, чтобы не устанавливать соединение каждые 5 секунд?Есть, если только сайт отдает информацию по websocket(не зашифрованному).
import requests
from bs4 import BeautifulSoup
url = 'https://koronavirusa.site/ru'
page = requests.get(url)
soup = BeautifulSoup(page.text, "html.parser")
container = soup.find('div', class_='sppb-container-inner')
data = container.find_all('div',class_='sppb-animated-number')
infected = data[0].text
died = data[1].text
healed = data[2].text
print(f'''Заражено: {infected}
Умерло: {died}
Выздоровело: {healed}''')Заражено: 1,990,746
Умерло: 125,919
Выздоровело: 466,997url = 'https://phys-ege.sdamgia.ru/test?filter=all&category_id=205'
responce = requests.post(url,data={'ajax':'1','skip':'10'})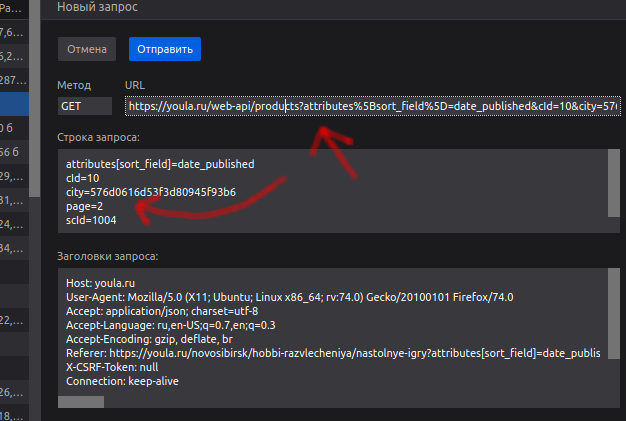
soup = BeautifulSoup(response.text,"lxml")
ul = soup.find('ul',id = 'sizes')
sizes = ul.find_all('li')
for size in sizes:
print(size.text.strip())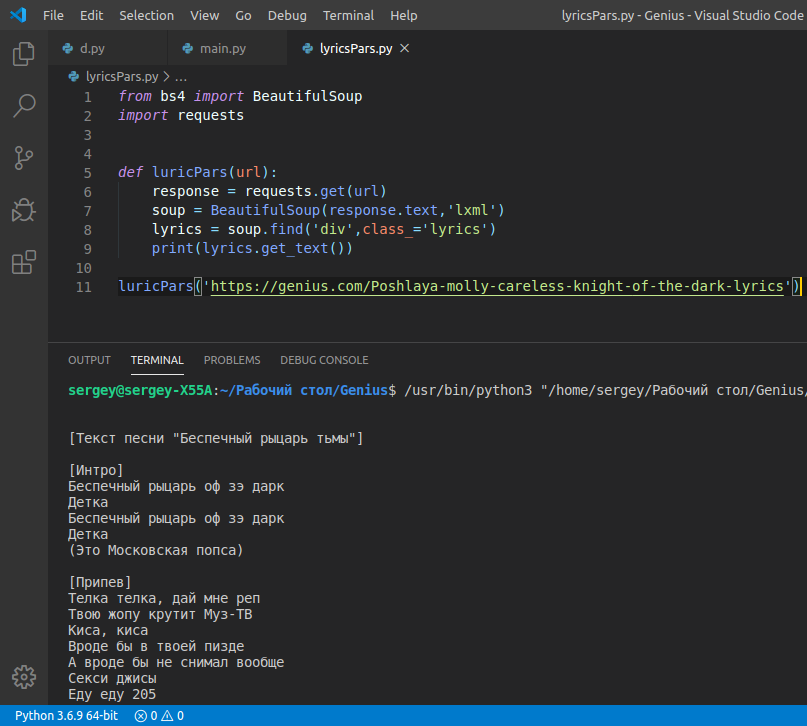
import requests
from bs4 import BeautifulSoup
from lxml import html
import csv
url = 'https://www.yoox.com/ru/%D0%B4%D0%BB%D1%8F%20%D0%BC%D1%83%D0%B6%D1%87%D0%B8%D0%BD/%D0%BE%D0%B4%D0%B5%D0%B6%D0%B4%D0%B0/shoponline#/dept=clothingmen&gender=U&page=1&season=X'
headers = {'user-Agent': 'Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:72.0) Gecko/20100101 Firefox/72.0',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
def getClothes(url,page_id):
clothes = []
respones = requests.get(url,headers=headers)
soup = BeautifulSoup(respones.text,'lxml')
mainContent = soup.find('div',id=f'srpage{page_id}')
products = mainContent.find_all('div',class_='col-8-24')
for product in products:
brand = product.find('div',class_='itemContainer')['data-brand'] # Бренд
cod10 = product.find('div',class_='itemContainer')['data-current-cod10'] # Для формирования ссылки yoox.com/ru/{cod10}/item
category = product.find('div',class_='itemContainer')['data-category'] # Категория
oldPrice = product.find('span',class_='oldprice text-linethrough text-light') # Старая цена (может не быть)
newPrice = product.find('span',class_='newprice font-bold') # Новая цена (может не быть)
if oldPrice is not None:
# Данный код выполняется только, если на товар есть скидка
sizes = product.find_all('div',class_='size text-light')
str_sizes = ''
for x in sizes:
str_sizes += x.text.strip().replace('\n',';')
clothes.append({'art':cod10,
'brand':brand,
'category':category,
'url':f'https://yoox.com/ru/{cod10}/item',
'oldPrice':oldPrice.text,
'newPrice':newPrice.text,
'sizes':str_sizes
})
return clothes
def getLastPage(url):
respones = requests.get(url,headers=headers)
soup = BeautifulSoup(respones.text,'lxml')
id = soup.find_all('li', class_ = 'text-light')[2]
return int(id.a['data-total-page']) + 1
def writeCsvHeader():
with open('yoox_man_clothes.csv', 'a', newline='') as file:
a_pen = csv.writer(file)
a_pen.writerow(('Артикул', 'Ссылка', 'Размеры', 'Бренд', 'Категория', 'Старая цена', 'Новая цена'))
def files_writer(clothes):
with open('yoox_man_clothes.csv', 'a', newline='') as file:
a_pen = csv.writer(file)
for clothe in clothes:
a_pen.writerow((clothe['art'], clothe['url'], clothe['sizes'], clothe['brand'], clothe['category'], clothe['oldPrice'], clothe['newPrice']))
if __name__ == '__main__':
writeCsvHeader() # Запись заголовка в csv файл
lastPage = getLastPage(url) # Получаем последнею страницу
for x in range(1,lastPage): # Вместо 1 и lastPage можно указать диапазон страниц. Не начинайте парсить с нулевой страницы!
print(f'Скачавается: {x} из {lastPage-1}')
url = f'https://www.yoox.com/RU/shoponline?dept=clothingmen&gender=U&page={x}&season=X&clientabt=SmsMultiChannel_ON%2CSrRecommendations_ON%2CNewDelivery_ON%2CRecentlyViewed_ON%2CmyooxNew_ON'
files_writer(getClothes(url,x)) # Парсим и одновременно заносим данные в csv
import requests
from bs4 import BeautifulSoup
url = 'https://coinmarketcap.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
all = soup.find_all('',class_='cmc-table-row')
for x in all:
rank = x.find('td',class_='cmc-table__cell--sort-by__rank').text
name = x.find('td',class_='cmc-table__cell--sort-by__name').text
market_cap = x.find('td',class_='cmc-table__cell--sort-by__market-cap').text
price = x.find('td',class_='cmc-table__cell--sort-by__price').text
volume = x.find('td',class_='cmc-table__cell--sort-by__volume-24-h').text
circulating_supply = x.find('td',class_='cmc-table__cell--sort-by__circulating-supply').text
change = x.find('td',class_='cmc-table__cell--sort-by__percent-change-24-h').text
print(f'{rank} {name} {market_cap} {price} {volume} {circulating_supply} {change}')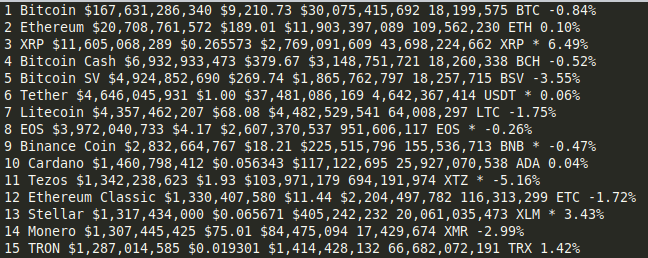
import requests
from bs4 import BeautifulSoup
url = 'https://coinmarketcap.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
all = soup.find_all('',class_='cmc-table-row')
for x in all:
rank = x.find('td',class_='rc-table-cell table-col-rank rc-table-cell-fix-left').text
name = x.find('a',class_='cmc-link').find('p').text
market_cap = x.find('td',class_='rc-table-cell font_weight_500___2Lmmi').text
price = x.find('td',class_='rc-table-cell font_weight_500___2Lmmi').text
volume = x.find('div',class_='Box-sc-16r8icm-0 sc-1anvaoh-0 gxonsA').a.p.text
circulating_supply = x.find('p',class_='Text-sc-1eb5slv-0 kqPMfR').text
# change = x.find('td',class_='cmc-table__cell--sort-by__percent-change-24-h').text
print(f'{rank} {name} {market_cap} {price} {volume} {circulating_supply}')