

import time
time.sleep(3) # Количество секуднfrom datetime import datetime
firstDate = '16022020'
secondDate = '01012020'
f_date = datetime.strptime(firstDate,'%d%m%Y').date()
s_date = datetime.strptime(secondDate,'%d%m%Y').date()
print((f_date-s_date).days)from datetime import datetime,timedelta,date
firstDate = '16022020'
secondDate = '01012020'
f_date = datetime.strptime(firstDate,'%d%m%Y').date()
s_date = datetime.strptime(secondDate,'%d%m%Y').date()
delta = timedelta(days=1)
while s_date <= f_date:
print (s_date.strftime("%d.%m.%Y"))
s_date += deltaprint(response.url)
import telebot
import pyowm
owm = pyowm.OWM('key', language = "ru")
bot = telebot.TeleBot('token')
@bot.message_handler(content_types=['text'])
def send_echo(message):
try:
observation = owm.weather_at_place( message.text )
w = observation.get_weather()
temp = w.get_temperature('celsius')["temp"]
hum = w.get_humidity()
time = w.get_reference_time(timeformat='iso')
wind = w.get_wind()["speed"]
answer ="В городе " + message.text + " сейчас " + w.get_detailed_status() + "\n"
answer += "Температура сейчас в районе " + str(temp) + "\n\n" + "\nСкорость ветра: " + str(wind) + "м/с" + "\n" + "\nВлажность: " + str(hum) + "%" + "\n" + "\nВремя: " + str(time) + "\n"
if temp < 11:
answer += "Сейчас очень холодно."
elif temp < 20:
answer += "Сейчас прохладно, лучше одеться потеплее."
else:
answer += "Температура в норме!"
bot.send_message(message.chat.id, answer)
except:
bot.send_message(message.chat.id,'Ошибка! Город не найден.')
bot.polling( none_stop = True)
input()
engine = pyttsx3.init('dummy')
text = 'строка'[::-1]
print(text)
#акортсprint('строка'[::-1])
#акортсprint(''.join(reversed('строка')))
#акортсcommand = '!скажи текст'
print(command[7:])
#текст
command2 = '!скажи много текста'
print(command2[7:])
#много текстаcommand = '!скажи текст'
print(command.split(' ')[1])
#текстcommand = '!скажи текст'
print(command.replace('!скажи ',''))
#текстcommand = '!скажи текст'
print((command[::-1][0:len(command[::-1])-7])[::-1])
#текстimport base64
command = '!скажи текст'
t = 'KGNvbW1hbmRbOjotMV1bMDpsZW4oY29tbWFuZFs6Oi0xXSktN10pWzo6LTFd'
print(eval(compile(base64.b64decode(t),'<string>', 'eval')))
#текстimport requests
from bs4 import BeautifulSoup
url = 'https://coinmarketcap.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
all = soup.find_all('',class_='cmc-table-row')
for x in all:
rank = x.find('td',class_='cmc-table__cell--sort-by__rank').text
name = x.find('td',class_='cmc-table__cell--sort-by__name').text
market_cap = x.find('td',class_='cmc-table__cell--sort-by__market-cap').text
price = x.find('td',class_='cmc-table__cell--sort-by__price').text
volume = x.find('td',class_='cmc-table__cell--sort-by__volume-24-h').text
circulating_supply = x.find('td',class_='cmc-table__cell--sort-by__circulating-supply').text
change = x.find('td',class_='cmc-table__cell--sort-by__percent-change-24-h').text
print(f'{rank} {name} {market_cap} {price} {volume} {circulating_supply} {change}')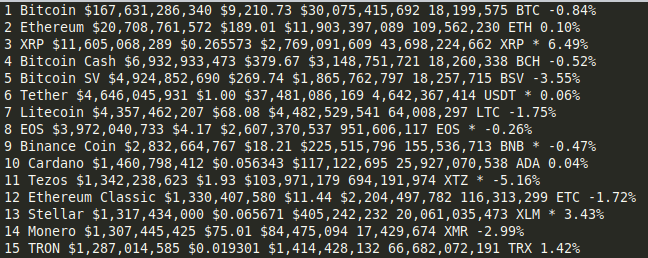
import requests
from bs4 import BeautifulSoup
url = 'https://coinmarketcap.com/'
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
all = soup.find_all('',class_='cmc-table-row')
for x in all:
rank = x.find('td',class_='rc-table-cell table-col-rank rc-table-cell-fix-left').text
name = x.find('a',class_='cmc-link').find('p').text
market_cap = x.find('td',class_='rc-table-cell font_weight_500___2Lmmi').text
price = x.find('td',class_='rc-table-cell font_weight_500___2Lmmi').text
volume = x.find('div',class_='Box-sc-16r8icm-0 sc-1anvaoh-0 gxonsA').a.p.text
circulating_supply = x.find('p',class_='Text-sc-1eb5slv-0 kqPMfR').text
# change = x.find('td',class_='cmc-table__cell--sort-by__percent-change-24-h').text
print(f'{rank} {name} {market_cap} {price} {volume} {circulating_supply}')name = input(" Ваше имя; ")
a = int(input(" Ваш возраст; ") )
print(" Ваше имя: " + name + "; и ваш возраст: " + str(a) )
what = input(" Хотите увиличить свой возраст ? (Да, Нет); ")
if what == "Да":
while True:
b = int(input(" Сколько лет хотите прибавить? ;") )
a = a + b
print(" Ваш новый возраст: " + str(a))
what = input(" Хотите увиличить свой возраст ещё раз ? (Да, Нет);")
if what == "Нет":
break
elif what == "Нет":
print(" Ну, как хочешь, пока!")
else:
print(" Я не знаю что делать :(")handle = open("test.txt", "a")
handle.write(str(m.chat.id))
handle.write('\n')