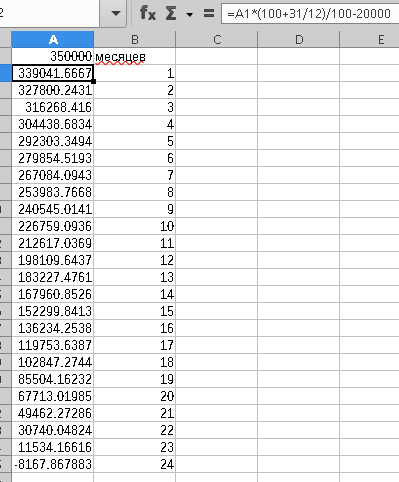
Непонятны только входные данные насчёт 5/2 и 2/2 - это ведь разное количество часов за смену.
Есть ли какая-то связь между длительностью смены и видом работы (давайте не будем называть это "нагрузкой", потому что такой термин создаёт путаницу смыслов)? Во всем вопросе ни разу не упомянуто количество рабочих часов, поэтому создаётся впечатление, что в рассматриваемом случае 25+15 не важно, 25 человек совершают звонки 8-часовую смену, или 25 человек совершают звонки 12-часовую смену, или любой промежуточный вариант.
Если отвлечься от разных рабочих смен (только учитывать разное количесво работников на день), то алгоритм очень простой Мозг понадобится лишь в коротенькие периоды, остальное - тупой кодинг.
k = количество видов работ
i=1..k
A = доступное количесво работников на день
W[i] это желаемая цель на день по видам работ
B = sum W[i]
V[i] это реализуемая цель
грубо V[i] = W[i] * A / B; тут важно: не спешить округлять "полтора землекопа" до int(W[i] * A / B); нужно напрячь мозг не более, чем на полторы минуты и более правильный способ округления станет очевиден (но поля этой книги слишком малы, чтоб его описать. Хе-хе).
Следующий этап.
Для каждого работника P[j] (j=1..A) считаем статистику за предыдущий период (с начала месяца или как захотим), сколько он занимался i-й работой. Получаем S[i,j].
Создаём k списков L работников, в каждом A работников. Сортируем каждый список L[i] по возрастанию S [i,j] (возможно, тут нужно на несколько минут включить мозг просто для повышения внимательности, т.к. сортировка выглядит чуточку необычно).
Последний этап.
Дёргаем из начала списка работника и назначаем на соответствующий вид работы (поскольку список уже отсортирован, то человек занимался этой работой меньше других). При этом удаляем этого работника из всех k списков. И уменьшаем W[i]. Повторяем, пока списки не пустые и пока W[i]>0. Для ещё более "гладкого" распределения последний раз на сегодня включаем мозг и перед каждым назначением сравнимаем отношения S[i,j] для элементов из начала и из конца каждого списка; в зависимости от результата сравнения выбираем, какой из списков будем дёргать на этом шаге (конкретную формулу не пишу, т.к. у мозга законный выходной).
Готово.
Возвращась к разным сменам: их учёт может усложнить алгоритм в полтора-два раза. Но сильно зависит от точных формулировок хотелок по этим сменам.