

import io
from lxml import etree
parser = etree.HTMLParser()
html = '''
<div class='user-data__about'>
<strong>UI/UX and Product Designer<br><br></strong><strong>Портфолио<br></strong>alexandr</a> > <a works</a><br>Экспертная область — дизайн мобильных приложений и web-интерфейсов.<br>Рисую дизайн для сайтов, мобильных и web-приложений. <br>Работаю с компаниями, студиями, стартапами.<br><br>Мне нравиться создавать поистине крутой продуктовый дизайн для своих клиентов. Погружаться в бизнес логику продукта и улучшать его качество. При этом развиваться как профессионал и оттачивать мастерство в любимом деле.<br><br><br><strong>Ссылки</strong><br><br><br><strong>Контакты</strong><br><strong><br>Услуги</strong><br><ul><li>UI/UX дизайн мобильных приложений и web-интерфейсов.</li><li>Адаптивный дизайн сложных CRM, SaaS(дашборды аналитики, таблицы)</li><li>Отрисовка иллюстраций.</li><li>Анимация интерфейсов.</li><li>Сотрудничество под NDA.</li></ul><br><strong>Инструменты</strong><br><ul><li>Figma</li><li>Sketch</li><li>After Effects</li></ul><strong><br>Примеры лучших работ<br></strong><br>Дизайн сайтов<br><br>Дизайн мобильных приложений<br>
</div>
'''
root = etree.parse(io.StringIO(html), parser=parser)
print(' '.join(root.xpath('.//text()')))import lxml.html
root = lxml.html.fromstring(html)
print([x.get('title') for x in root.xpath('.//td/div')])['Ясно', 'Ясно', 'Облачно с прояснениями', 'Облачно с прояснениями', 'Облачно с прояснениями',
'Облачно с прояснениями, дождь', 'Облачно с прояснениями, дождь', 'Облачно с прояснениями']driver.get('http://lenta.ru')
driver.execute_script('''
var aTags = document.getElementsByTagName("a");
for (var i = 0; i < aTags.length; i++) {
if (aTags[i].innerText.startsWith("07:50Опубликованы данные")) {
aTags[i].innerText = "Утки с Марса захватили вселенную!";
break;
}
}
''')
time.sleep(1)
screenshot = driver.get_screenshot_as_png()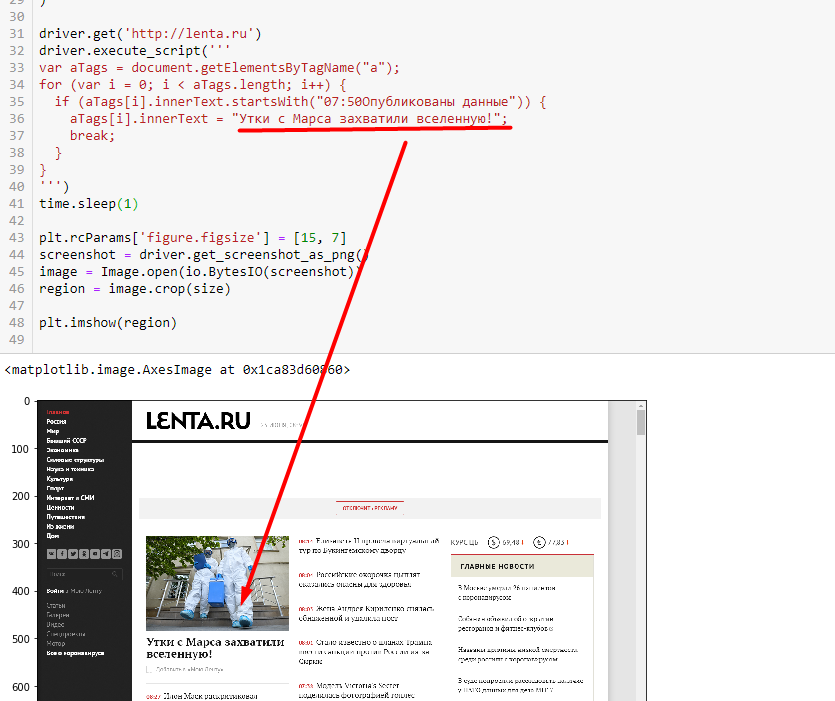
...
driver.get('https://www.avito.ru/rostov-na-donu/zapchasti_i_aksessuary/akpp_infiniti_vq37vhr_g37_1791599363')
el = driver.find_element_by_xpath("//button[contains(@data-marker, 'item-phone-button/card')]")
el.click()
el = driver.find_element_by_xpath("//img[contains(@data-marker, 'phone-popup/phone-image')]")
image = Image.open(io.BytesIO(base64.b64decode(el.get_attribute('src').split(',')[1])))
imshow(image)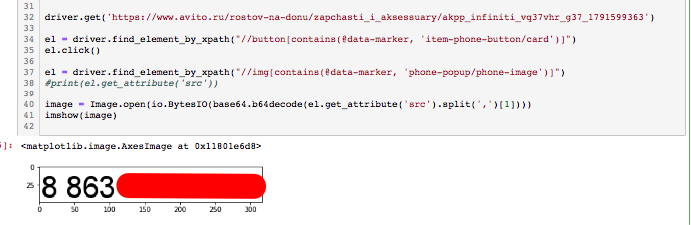
Что является быстрым и удобным спомобом для парсинга сайтов, php или nodejs
from lxml import etree
str1 = """<div class="cl-pagination">
...
</div>"""
root = etree.fromstring(str1)
print(root.xpath('.//ul/li[last()-1]/a')[0].text)print(root.xpath('.//ul/li[not(contains(@class, "next-page")) and not(contains(@class, "previous-page"))]/a')[-1].text)str1 = ('\n\nACES Direct | zakelijk\n Gratis retour binnen 60 dagen.\n', '\n€ 1.700,05')
print(str1[0].replace('\n',''), '-', str1[1].replace('\n',''))import re
str1="""<тег>1</тег><тег>2</тег><тег>3</тег>"""
for res in re.findall(r'<тег>(.*?)<\/тег>', str1):
print(res)>>> import lxml.html
>>> str1 = """
... <tr>
... <td>99</td>
... <td>Name</td>
... <td>ЕГЭ</td>
... <td>268</td><td>90</td><td>91</td><td>87</td>
... <td></td>
... <td>Копия</td>
... <td>Нет</td>
... </tr>"""
>>> root = lxml.html.fromstring(str1)
>>> [x.text for x in root.xpath('.//td')]
['99', 'Name', 'ЕГЭ', '268', '90', '91', '87', None, 'Копия', 'Нет']import re
import pprint
import requests
import lxml.html
URL = 'http://www.asu.ru/timetable/students/32/2129436778/'
pp = pprint.PrettyPrinter(indent=4)
res = requests.get(URL)
root = lxml.html.fromstring(res.text)
table = list()
elems = root.xpath('.//tr[@class="schedule-date"]|.//tr[@class="schedule-time"]')
curr_date = ''
for el in elems:
if el.get('class') == 'schedule-date':
curr_date = el.xpath('.//span[1]')[0].text
if el.get('class') == 'schedule-time':
out = re.sub(' +', ' ', ''.join(el.itertext()))
out = re.sub('^\s+', '', out)
out = re.sub('\n+', '', out)
table.append({'date': curr_date, 'info': out})
pp.pprint(table)[ { 'date': 'Понедельник',
'info': '4 13:20 - 14:50 лек. Физические методы исследования '
'проф. Смагин В.П. 500\xa0К дата изменения: 08.04.2019 '
'11:21 свободные аудитории '},
{ 'date': 'Понедельник',
'info': '2 09:40 - 11:10 а) лаб. Новые информационные '
'технологии преп. Кушнир Е.Ю. 417\xa0К дата '
'изменения: 24.04.2019 11:16 свободные аудитории '},
{ 'date': 'Понедельник',
'info': '3 11:20 - 12:50 пр.з. Социология доц. Артюхина '
'В.А. 311а\xa0К дата изменения: 24.04.2019 11:13 '
'свободные аудитории '},
{ 'date': 'Вторник',
'info': '3 11:20 - 12:50 пр.з. Социология доц. Артюхина '
'В.А. 311а\xa0К дата изменения: 24.04.2019 11:13 '
'свободные аудитории '},
{ 'date': 'Вторник',
'info': '1 08:00 - 09:30 пр.з. Педагогика доц. Зацепина '
'О.В. 311а\xa0К дата изменения: 24.04.2019 11:11 '
'свободные аудитории '},
{ 'date': 'Вторник',
'info': '2 09:40 - 11:10 пр.з. Педагогика доц. Зацепина '
'О.В. 311а\xa0К дата изменения: 24.04.2019 11:07 '
'свободные аудитории '},
{ 'date': 'Вторник',
'info': '3 11:20 - 12:50 пр.з. Кристаллохимия доц. Стручева '
'Н.Е. 106а\xa0К дата изменения: 24.04.2019 11:06 '
'свободные аудитории '},
{ 'date': 'Среда',
'info': '3 11:20 - 12:50 пр.з. Кристаллохимия доц. Стручева '
'Н.Е. 106а\xa0К дата изменения: 24.04.2019 11:06 '
'свободные аудитории '},
{ 'date': 'Среда',
'info': '3 11:20 - 12:50 а) лаб. Новые информационные '
'технологии преп. Кушнир Е.Ю. 419\xa0К дата '
'изменения: 08.04.2019 11:21 свободные аудитории '},
{ 'date': 'Среда',
'info': 'б) лаб. Новые информационные технологии доц. Геньш К.В. '
'417\xa0К дата изменения: 08.04.2019 11:21 свободные '
'аудитории '},
{ 'date': 'Среда',
'info': '4 13:20 - 14:50 б) лаб. Новые информационные '
'технологии доц. Геньш К.В. 417\xa0К дата '
'изменения: 24.04.2019 11:18 свободные аудитории '},
{ 'date': 'Четверг',
'info': '4 13:20 - 14:50 б) лаб. Новые информационные '
'технологии доц. Геньш К.В. 417\xa0К дата '
'изменения: 24.04.2019 11:18 свободные аудитории '},
{ 'date': 'Четверг',
'info': '2 09:40 - 11:10 а) пр.з. Аналитическая химия доц. '
'Лейтес Е.А. 500\xa0К дата изменения: 29.04.2019 '
'10:56 свободные аудитории '},
{ 'date': 'Четверг',
'info': '3 11:20 - 12:50 пр.з. Физические методы исследования '
'проф. Смагин В.П. 521\xa0К дата изменения: 24.04.2019 '
'11:15 свободные аудитории '},
{ 'date': 'Четверг',
'info': '4 13:20 - 14:50 б) пр.з. Аналитическая химия проф. '
'Смагин В.П. 508\xa0К дата изменения: 29.04.2019 '
'10:55 свободные аудитории '},
{ 'date': 'Пятница',
'info': '4 13:20 - 14:50 б) пр.з. Аналитическая химия проф. '
'Смагин В.П. 508\xa0К дата изменения: 29.04.2019 '
'10:55 свободные аудитории '},
{ 'date': 'Пятница',
'info': '1 08:00 - 09:30 а) лаб. Аналитическая химия доц. '
'Лейтес Е.А. 509\xa0К дата изменения: 29.04.2019 '
'10:55 свободные аудитории '},
{ 'date': 'Пятница',
'info': 'б) лаб. Аналитическая химия проф. Смагин В.П. 508\xa0'
'К дата изменения: 29.04.2019 10:55 свободные '
'аудитории '},
{ 'date': 'Пятница',
'info': '2 09:40 - 11:10 а) лаб. Аналитическая химия доц. '
'Лейтес Е.А. 509\xa0К дата изменения: 29.04.2019 '
'10:54 свободные аудитории '},
{ 'date': 'Пятница',
'info': 'б) лаб. Аналитическая химия проф. Смагин В.П. 508\xa0'
'К дата изменения: 29.04.2019 10:53 свободные '
'аудитории '},
{ 'date': 'Пятница',
'info': '3 11:20 - 12:50 а) лаб. Аналитическая химия доц. '
'Лейтес Е.А. 509\xa0К дата изменения: 29.04.2019 '
'10:53 свободные аудитории '},
{ 'date': 'Пятница',
'info': 'б) лаб. Аналитическая химия проф. Смагин В.П. 508\xa0'
'К дата изменения: 29.04.2019 10:52 свободные '
'аудитории '},
{ 'date': 'Пятница',
'info': '4 13:20 - 14:50 лек. Физические методы исследования '
'проф. Смагин В.П. 500\xa0К дата изменения: 08.04.2019 '
'11:21 свободные аудитории '}]import os
from selenium import webdriver
DRIVER_PATH = os.path.join('c:\\', 'utils', 'chromedriver.exe')
options = webdriver.ChromeOptions()
options.add_argument('headless')
options.add_argument('start-maximized')
options.add_argument('window-size=2048x5000')
browser = webdriver.Chrome(executable_path=DRIVER_PATH, options=options)
browser.get('https://lime-shop.ru/shops/moskva/')
browser.implicitly_wait(10)
for el in browser.find_elements_by_xpath("//div[@class='shops__place']"):
print(el.text)
print('-' * 30)
ALTER DATABASE dbname CHARACTER SET utf8 COLLATE utf8_general_ci;
ALTER TABLE tablename CHARACTER SET utf8 COLLATE utf8_general_ci;