и умоляю, никаких «заливать по ФТП на продакшен». это обязательно выйдет боком в самый неподходящий момент.
public class AsyncServlet extends HttpServlet {
private static String HEAVY_RESOURCE
= "This is some heavy resource that will be served in an async way";
protected void doGet(
HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
ByteBuffer content = ByteBuffer.wrap(
HEAVY_RESOURCE.getBytes(StandardCharsets.UTF_8));
AsyncContext async = request.startAsync();
ServletOutputStream out = response.getOutputStream();
out.setWriteListener(new WriteListener() {
@Override
public void onWritePossible() throws IOException {
while (out.isReady()) {
if (!content.hasRemaining()) {
response.setStatus(200);
async.complete();
return;
}
out.write(content.get());
}
}
@Override
public void onError(Throwable t) {
getServletContext().log("Async Error", t);
async.complete();
}
});
}
}Нет, так не бывает. Хочешь обрабатывать множество одновременных соединений, готовься к трудностям.
асинхронные сервлеты - это просто способ переложить нагрузку с одного пула потоков на другой
WebFlux, который работает поверх Netty
Можно и сервлеты писать в реактивном стиле.
А вот Netty и Vert.x работают на других принципах и способны обрабатывать 10 000 и более одновременных соединений, но за счёт увеличения сложности.
обсуждению протокола http. Этот протокол проектировался под взаимодействие в режиме вопрос-ответ без сохранения состояния. Так его желательно и использовать.
клиент открывает долгоживущее HTTP-соединение, которое хранится на сервере до того момента, пока сервер не будет готов отослать ответ обратно
Reverse AJAX избавляет нас от необходимости все время опрашивать сервер — соединение открывается один раз, и потом сервер сам отошлет ответ, когда будет что отсылать. Естесственно, когда с сервера придет ответ, нужно установить соединение заново.
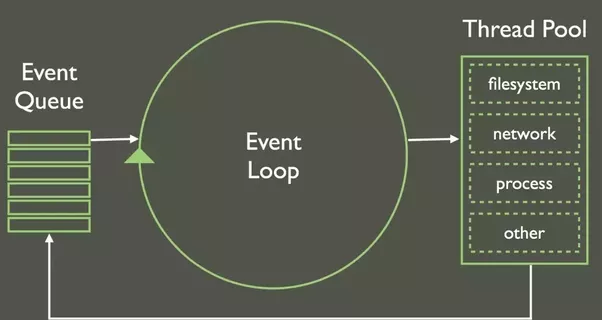
Обычно такую проблему решают отправкой тяжёлых заданий в очередь, из которой другой процесс (возможно даже на другом сервере) выбирает задания и выполняет
libuv has a default thread pool size of 4, and uses a queue to manage access to the thread pool - the upshot is that if you have 5 long-running DB queries all going at the same time, one of them (and any other asynchronous action that relies on the thread pool) will be waiting for those queries to finish before they even get started
На собеседовании спросили. "Поскольку объект меняет местоположение в памяти, как же дефолтовый хеш код остается неизменным, если он завязан на память"
конкретнее нет информации?
Ну для тебя не рокетсайнс, а для других еще пока рокет...
Вот люблю я наши( не западные всмысле) ресурсы, никогда прямо не скажут ничего, отошлют к первоисточникам. Наверное поэтому там мало литературы написано нашими авторами. У них видимо одно на уме: "ребята, хотите изучить джаву? нет проблем, открываем исходники и читаем. Конец книги."