Ох...
Model View Controller. Да ну его, ему уже 45 лет (придумали в 79-ом году). Давайте лучше про
Model View Adapter погокорим. это то что все используют в популярных фреймворках последние лет так 10 так точно.
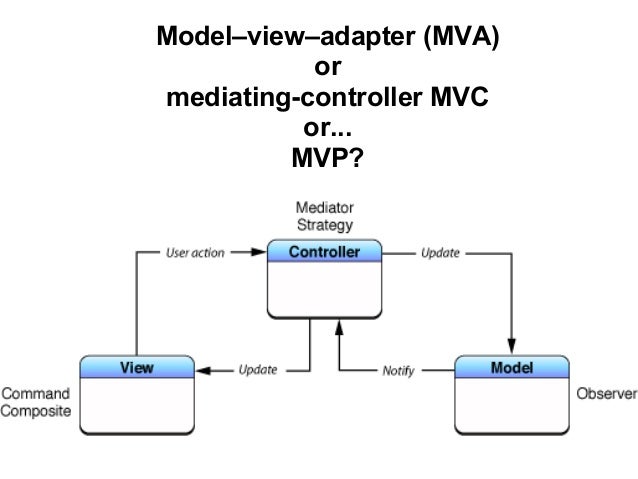
Вообще в этом всем важно не только то, что каждая буква обозначает, а как они друг с дружкой связаны.
View - это
не только HTML, но и вообще представление в целом, а так же логика его формирования. Шаблонизаторы, фильтры, различные функции/объекты помогаютщие нам сформировать view (например форматирование дат, сериализаторы и т.д.) В подавляющем большинстве случаев "представление" наших данных - это HTTP запросы и HTTP ответы. HTML - э то лишь часть HTTP ответа.
Model - Это целый слой, который может быть представлен в виде кучи отдельных объектиков, структур и т.д. Его задача - делать дела и хранить/менять состояние системы. Тут легко запутаться потому что термин "модель" много чего значит. Воспринимайте его как "слой логики" а не конкретные объекты. И да - база данных и прочая чушь - это детали реализации этого слоя. "не важные штуки" словом. Туда же и ActiveRecord, ORM-ки всякие. Это деталь реализации и все остальные чуваки (view и controller) о них знать ничего не должны (хотя иногда могут в целях упрощения).
Controller или адаптер. Это опять же не обязательно один объект. это может быть цепочка адаптеров (еще называют фронт-контроллером, middlewares и т.д.). Его задача весьма простая. Получаем представление данных на входе (HTTP запрос), определяем что надо делать, и просим модель что-то сделать (ни в коем случае не меняем ничего самостоятельно в контроллере, он только просит). Потом мы можем попросить модель вернуть нужный нам кусок состояния, и попросить View сформировать представление (HTTP ответ).
Как-то так. В целом же это я сейчас описал "идеальный мир". Вся суть этого подхода - разделение логики презентационной и логики приложения. Зачем это надо? что бы было проще жить! Обычно UI приложения или способы взаимодействия с ним меняются почаще логики или как минимум в разные моменты времени. Адаптеры в этом случае служат промежуточным слоем, они ничего сами не делают, это "переводчики". Они просто переводят то, что сказано в запросе в язык понятный приложению и обратно.
Но на начальной стадии можно слегка нарушать эти правила, делать толстые контроллеры и т.д. В этом случае бизнес логика будет потихоньку "вытекать" из модели. Это не хорошо, и на хоть сколько нибудь больших проектах может привести к проблемам. Потому важно находить баланс.













