Первый вопрос: скажите пожалуйста правильно ли я построил схему работу с базой?
Такой подход имеет право на жизнь и часто встречается у новичков. Но он не очень удобен в использовании и поддержке.
Второй вопрос: у меня после каждого запроса в терминале висит куча Sleep соединений
Сложно сказать в чём дело по тем данным что вы предоставили. Возможно con.close() выдал исключение и не закрыл соединение, а у вас это исключение тупо игнорируется.
В однопоточных приложениях распространена практика открыть одно соединение и работать с ним всё время, пока приложение работает. То есть примерно так:
package hello.world;
import java.sql.*;
public class Main {
// один коннект на всё приложение
private static Connection conn;
// в данном случае так же можно использовать и единственный Statement
private static Statement stmt;
public static void main(String[] args) throws SQLException {
conn = DriverManager.getConnection("jdbc:mysql://localhost/hello", "user", "password");
stmt = conn.createStatement();
doTheJob();
}
private static void doTheJob() throws SQLException {
// здесь используется фишка Java7 под названием try-with-resources,
// которая освобождает нас от необходимости закрывать ResultSet руками
// он будет закрыт автоматически в конце try блока
try ( ResultSet rs = stmt.executeQuery("SHOW TABLES") ) {
while ( rs.next() ) {
System.out.println(rs.getString(1));
}
}
// переиспользуем Statement для другого запроса - это допустимо
try ( ResultSet rs = stmt.executeQuery("SELECT column FROM table") ) {
while ( rs.next() ) {
System.out.println(rs.getString(1));
}
}
// вариант без try-with-resources для Java6 и ниже
ResultSet rs2 = null;
try {
rs2 = stmt.executeQuery("SELECT column2 FROM table2");
// делаем что-то с rs2
} finally {
close(rs2);
}
}
private static void close(ResultSet rs) {
if ( rs != null ) {
try {
rs.close();
} catch ( SQLException e ) {
e.printStackTrace();
}
}
}
}
То есть закрывать коннект к базе после каждого запроса совершенно необязательно. В некоторых случаях это даже вредно, потому что открытие нового коннекта занимает некоторое время и при большом количестве запросов этот оверхед становится заметным.
Для многопоточных программ часто используется схожая техника, где у каждого потока есть свой объект Connection, с которым он работает (например, хранит свой экземпляр коннекта в ThreadLocal поле).
Но в многопоточных приложениях удобнее пользоваться пулом коннектов. Пул берёт на себя ответственность по раздаче соединений всем страждущим. Он на старте создаёт сразу несколько соединений к базе и сохраняет в свою внутреннюю коллекцию. Далее, по мере необходимости (вызова метода getConnection на пуле), пул удаляет из внутренней коллекции первый по очереди коннект и возвращает его запросившему. Если колекция пуста, то создаётся новый коннект и сразу возвращается. Основная фишка в том, что возвращаемые этим пулом соединения при закрытии на самом деле на закрываются, а возвращаются обратно во внутреннюю коллекцию пула и могут быть переиспользованы другими потоками. Таким образом достигается более высокая производительность путём уменьшения количества открытых коненктов к базе и увеличения интенсивности их использования. Код приложения при этом выглядит так, будто на каждый запрос строится новое соединение к базе и закрывается сразу после завершения работы с результатом этого запроса.
Разумеется, описание в предыдущем абзаце довольно поверхностное и неполное, но обрисовывает общую для всех пулов концепцию.
Если будете заниматься многопоточным программированием, а это маст хэв для backend (в особенности, highload), то без пула коннектов не обойтись. Хотя конечно можно и обойтись, но по мере развития проекта вы будете пилить собственную обёртку и в итоге реализуете самый простейший пул коннектов. Оно того не стоит - проще сразу взять готовый.
Я не рекомендую сразу браться за изучение каких-либо пулов. Сначала попрактикуйтесь с голым JDBC в однопоточных приложениях. Пулы коннектов - это уже вторая ступень. К ним следует приступать только когда будете уверенно себя чувствовать в JDBC. На начальном этапе они будут только мешать.
Когда будете готовы освоить какой-нибудь пул, то советую обратить внимание на
HikariCP. Он давно уже работает у меня в хайлоад проектах и ни разу не подводил. Ниже пример кода с его использованием:
package hello.world;
import com.zaxxer.hikari.HikariConfig;
import com.zaxxer.hikari.HikariDataSource;
import java.sql.*;
import java.util.Properties;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class Main {
// пул, в котором содержатся все соединения
private static HikariDataSource dbPool;
// в этом сервисе будем параллельно выполнять запросы
private static ExecutorService executor = Executors.newFixedThreadPool(5);
public static void main(String[] args) throws SQLException {
// конфигурируем пул
Properties props = new Properties();
props.setProperty("dataSourceClassName", "com.mysql.jdbc.jdbc2.optional.MysqlDataSource");
props.setProperty("dataSource.url", "jdbc:mysql://localhost/hello");
props.setProperty("dataSource.user", "user");
props.setProperty("dataSource.password", "password");
props.setProperty("poolName", "MyFirstPool");
props.setProperty("maximumPoolSize", "5"); // в этом пуле будет максимум 5 соединений
props.setProperty("minimumIdle", "1"); // как минимум одно активное соединение там будет жить постоянно
dbPool = new HikariDataSource(new HikariConfig(props));
doTheJob();
}
private static void doTheJob() throws SQLException {
// сколько запросов будем делать параллельно
int selects = 5;
// этот объект позволит нам дождаться выполнения всех запросов,
// выполняющихся в параллельных потоках чтобы подсчитать общее время
// выполнения всех запросов
CountDownLatch waitLatch = new CountDownLatch(selects);
long startTime = System.nanoTime();
for ( int i = 0; i < selects; ++i ) {
executor.submit(new ThreadPoolJob(dbPool, waitLatch));
}
try {
// ждём когда все воркеры закончат
waitLatch.await();
} catch ( InterruptedException e ) {
System.out.println("latch was broken by interruption request");
}
long timeElapsed = System.nanoTime() - startTime;
System.out.println("All queries was executed in: " + (timeElapsed / 1000000000) + " sec");
}
// класс-воркер, который будет выполнять запрос
private static class ThreadPoolJob implements Runnable {
private final HikariDataSource dbPool;
private final CountDownLatch waitLatch;
ThreadPoolJob(HikariDataSource dbPool, CountDownLatch waitLatch) {
this.dbPool = dbPool;
this.waitLatch = waitLatch;
}
@Override
public void run() {
String tName = Thread.currentThread().getName();
System.out.println(tName + ": Start query");
try (
Connection conn = dbPool.getConnection();
Statement stmt = conn.createStatement();
) {
// здесь мы не получаем и не работаем с ResultSet, поэтому не
// описываем его в try-with-resources
stmt.execute("SELECT SLEEP(5)");
System.out.println(tName + ": Query completed");
} catch ( SQLException e ) {
e.printStackTrace();
} finally {
waitLatch.countDown();
}
}
}
}


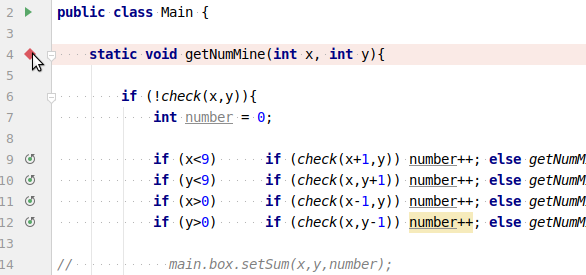
 (на скриншоте я уже проехал несколько шагов вперёд)
(на скриншоте я уже проехал несколько шагов вперёд)