Мне кажется вам рановато решать такие задачиНачну с того что я не программист, чтобы решать какие-то задачи. Я обычный пользователь ПК который шарит про IT чуть больше чем основная масса людей. Погуглив как пользоваться регулярками стало конечно яснее, но 100% просвещения я не получил. Пользуюсь я ими прямо в текстовом редакторе, а не в программировании.
Вы не написали для чего вам это нужно.Писал но совсем немного
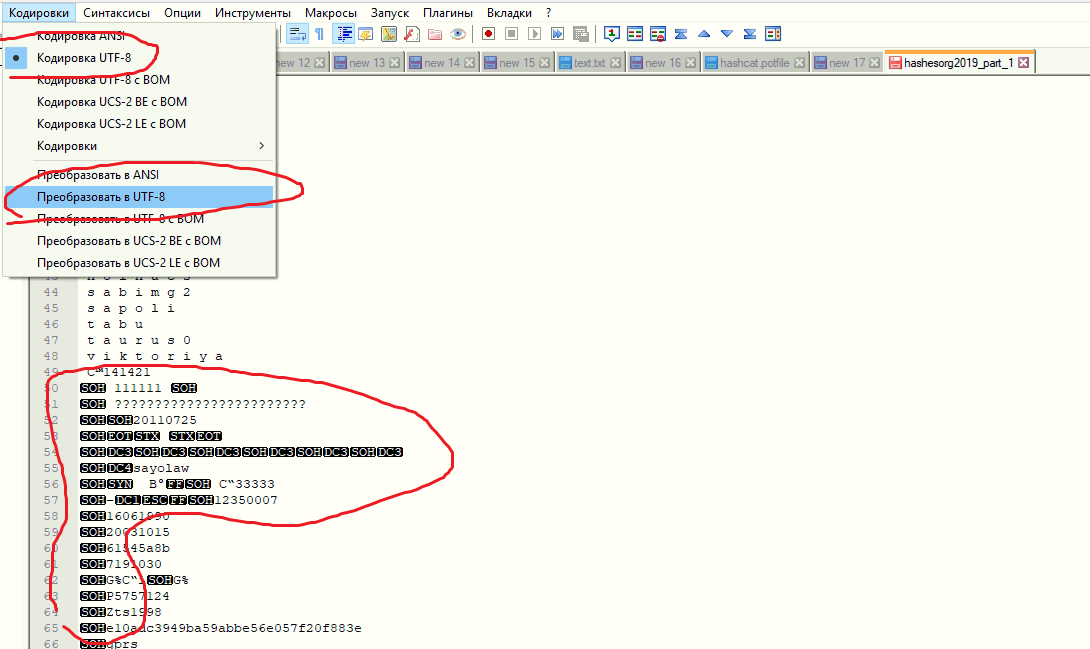
И да... это база для брута handshake'ов.И уже из этого можно понять что
не понимая как рабаотают регулярные выраженияПравда какое это вообще имеет значение я не понимаю.
Нафига всё лепить в один регексп мне не понятно.Я всего лишь хочу составить хороший алгоритм(регулярку) чтобы чистить базы для
брута handshake'овот мусора. Поэтому я зашел в интернет чтобы решить эту задачу с помощью понимающих больше меня в этом людей.
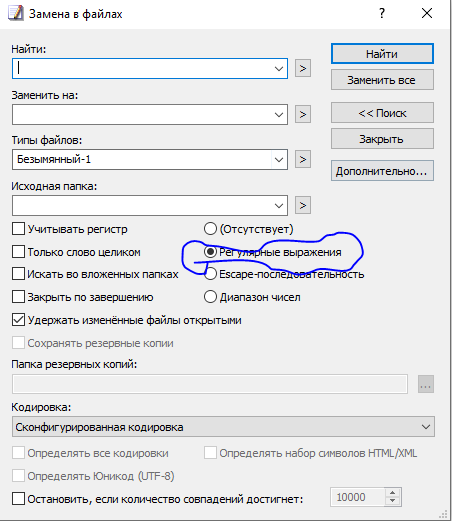
Работайте в utf-8Не так то просто менять кодировку в файлах которые весят по 80 гб. Да и не помогло это.
В вашем регэкспе подходящая конструкция встречалась, но, похоже вы этот регексп откуда-то срисовали или кто-то вам подсказал.Да. Я гуглил, копировал, и дорабатывал под себя.
Вам же нужно более одного.Да. Это я и писал выше.
[^\x00-\x7F]+ на пустоту но в базе всё равно остались какие-то непонятные символы.
\t* удаляет даже одиночные пробелы.[^\x00-\x7F]+
^(.{0,7})\r?\n
^([0-9]{8})\r?\n
.*htt(p:|ps:).*\r?\n
.*www\..*\r?\n
.*htt(p:|ps:).*\r?\n
.*mail.*\r?\n
.*@.*\r?\n| |? Получается уберутся не ascii символы и в некоторых строках появятся числа состоящие из 8 цифр или строки с меньше чем 8 символов, а эта проверка уже перейдёт на новую строку. И получается нужно будет по несколько раз проверять документ? А если я помещу [^\x00-\x7F]+ в конец регулярного выражения, то выходит что текстовый редактор сначала проверит на наличие 8 символов, и только потом проверит на наличие "не ascii" символов?