import requests
from requests.exceptions import ConnectionError
from time import sleep
import json
import sys
# Метод для корректной обработки строк в кодировке UTF-8 как в Python 3, так и в Python 2
if sys.version_info < (3,):
def u(x):
try:
return x.encode("utf8")
except UnicodeDecodeError:
return x
else:
def u(x):
if type(x) == type(b''):
return x.decode('utf8')
else:
return x
ReportsURL = 'https://api.direct.yandex.ru/live/v4/json/'
token = 'ВАШ СУПЕР ТОКЕН'
clientLogin = 'ЛОГИН ДО СОБАКИ'
headers = {
"Authorization": "Bearer " + token,
"Client-Login": clientLogin,
"Accept-Language": "ru",
# 'processingMode': 'auto'
}
body = {
"method": "AccountManagement",
"token": token,
"param": {
"Action": "Get",
"SelectionCriteria": {
'Logins': [
clientLogin,
],
},
},
'locale' : "ru",
}
json_body = json.dumps(body, indent=4)
try:
req = requests.post(ReportsURL, json_body, headers=headers)
req.encoding = 'utf-8'
if req.status_code == 200:
print("Отчет создан успешно")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("Содержание отчета: \n{}".format(u(req.text)))
print("JSON-код запроса: {}".format(u(body)))
print("JSON-код ответа сервера: \n{}".format(u(req.json())))
else:
print("Произошла непредвиденная ошибка")
print("RequestId: {}".format(req.headers.get("RequestId", False)))
print("JSON-код запроса: {}".format(body))
print("JSON-код ответа сервера: \n{}".format(u(req.json())))
amount = json_response["data"]["Accounts"][0]["Amount"]
print("Balans: " + amount)
except ConnectionError:
# В данном случае мы рекомендуем повторить запрос позднее
print("Произошла ошибка соединения с сервером API")
# Принудительный выход из цикла
# Если возникла какая-либо другая ошибка
except Exception as e:
# В данном случае мы рекомендуем проанализировать действия приложения
print("Произошла непредвиденная ошибка - 1")
print(e)
# Принудительный выход из цикла
/**
* Открывает URL и возращает код страницы
* Telegram - @ProgrammerForever
*
* @param {string} URL URL который нужно открыть
* @param {boolean} isCut Указывакт, нужно ли обрезать страницу до 50000 символов по длине, по умолчанию false
* @param {boolean} noScript Указывакт, нужно ли удалять скрипты из кода
* @return Исходный код страницы
* @customfunction
*/
function getHTML(URL,isCut,noScript) {
if ((URL === undefined)||(URL == "")) { return "#ОШИБКА Пустой URL";};
if (isCut === undefined) {var isCut=true;};
if (noScript === undefined) {var noScript=true;};
if (URL.map){ //Если задан диапазон
return URL.map(getHTML);
}else{
try {
var payload = {
'rand':(new Date()).getTime()
};
var headers={
'Connection': 'keep-alive',
'Cache-Control': 'max-age=0',
'Upgrade-Insecure-Requests': 1,
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'ru-RU,ru;q=0.9,en-US;q=0.8,en;q=0.7'
};
var options = {
'method' : 'get',
'headers' : headers,
'payload': payload
};
var response = UrlFetchApp.fetch(URL,options);
var charset=response.getAllHeaders["charset"];
//var responseText=response.getContentText(charset?charset:"windows-1251");
var responseText=response.getContentText(charset?charset:"UTF-8");
if (noScript){
responseText=responseText.replace(/<script[^>]*>(?:(?!<\/script>)[^])*<\/script>/gmi,"");
responseText=responseText.replace(/<!--.*?-->/gmi,"");
responseText=responseText.replace(/<link.*?\/>/gmi,"");
responseText=responseText.replace(/<meta.*?\/>/gmi,"");
responseText=responseText.replace(/[\n\r\t]/gmi,"");
};
if (isCut&&(responseText.length>50000)){return responseText.substring(0,50000);}else{return responseText;};
} catch (err) {
//return JSON.stringify(err);
return "#ОШИБКА "+err.message;
};
};
};$ python
Python 3.10.2 (main, Mar 8 2022, 23:56:15) [GCC 10.2.1 20210110] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import pandas as pd
>>> df = pd.DataFrame([[1,2,3],[3,4,5]])
>>> df
0 1 2
0 1 2 3
1 3 4 5
>>> df.values.tolist()
[[1, 2, 3], [3, 4, 5]]
const newArr = arr.map(function(n) {
return [ ...n, ...Array(this - n.length).fill('') ];
}, Math.max(...arr.map(n => n.length)));const max = arr.reduce((max, { length: n }) => max > n ? max : n, 0);
arr.forEach(n => n.push(...Array(max - n.length).fill('')));//Имя столбца по его номеру
function col2A1(col){
let result = "";
let base = 27;
while(col>0){
let newLetter = String.fromCharCode("A".charCodeAt(0)+(col-1)%(base-1));
result=newLetter + result;
col = (col - col%base) / base;
};
return result;
};
// или короткая версия
function col2A1_(r){let o="";for(;0<r;){var t=String.fromCharCode("A".charCodeAt(0)+(r-1)%26);o=t+o,r=(r-r%27)/27}return o}
/**
* @see https://gist.github.com/penguinboy/762197#gistcomment-3448642
*/
function flatten(object, path = null, separator = '.') {
return Object.keys(object).reduce((acc, key) => {
const value = object[key];
const newPath = Array.isArray(object)
? `${path ? path : ''}[${key}]`
: [path, key].filter(Boolean).join(separator);
const isObject = [
typeof value === 'object',
value !== null,
!(value instanceof Date),
!(value instanceof RegExp),
!(Array.isArray(value) && value.length === 0),
].every(Boolean);
return isObject
? { ...acc, ...flatten(value, newPath, separator) }
: { ...acc, [newPath]: value };
}, {});
}/**
*
*/
function myFunction() {
const response = {
result: {
items: [
{
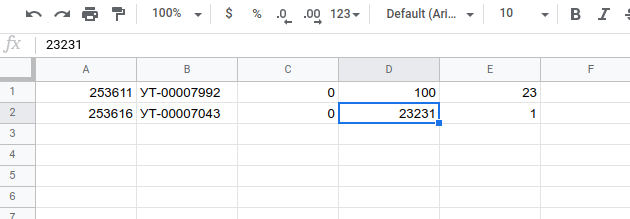
product_id: 253611,
offer_id: 'УТ-00007992',
stock: {
coming: 0,
present: 100,
reserved: 23,
},
},
{
product_id: 253616,
offer_id: 'УТ-00007043',
stock: {
coming: 0,
present: 23231,
reserved: 1,
},
},
],
total: 20,
},
};
const arr = response['result']['items'];
const data = [];
arr.forEach((el) => data.push(Object.values(flatten(el))));
SpreadsheetApp.getActive()
.getSheetByName('имя')
.getRange(1, 1, data.length, data[0].length)
.setValues(data);
}
import requests
url = 'https://cb-api.ozonru.me/v2/finance/transaction/list'
headers = {'client-id': '836', 'api-key': '0296d4f2-70a1-4c09-b507-904fd05567b9'}
data ={"filter": {
"date": {
"from": "2020-10-01T07:14:11.897Z",
"to": "2020-10-31T07:14:11.897Z"
},
"transaction_type": "all"
},
"page": "1",
"page_size": "10"
}
r = requests.post(url, json=data, headers=headers)