res2001, Я имею в виду, что это будет не совсем корректно в рамках поставленной задачи, так как по условию подразумевается, что входные данные - список и число.
res2001, я поэтому на нижней строчке скрина и привел время его исполнения. Но не уверен, что убирать его будет корректно, все таки, по умолчанию, мы работаем со стандартными типами данных, то есть это тоже относится к функции - преобразование в np.array
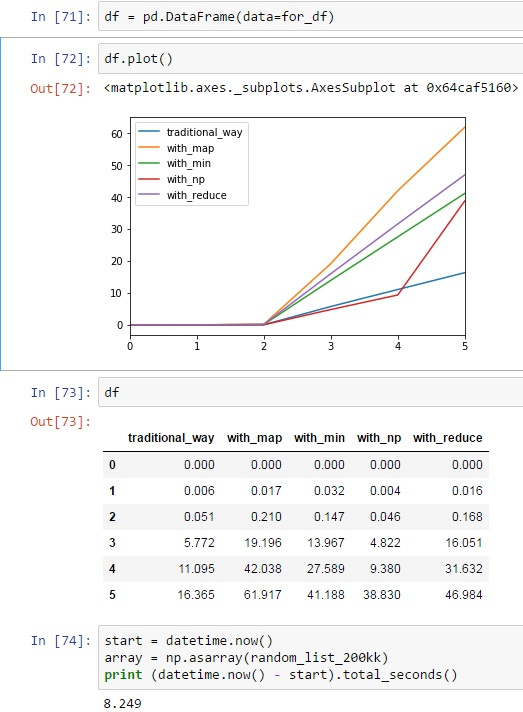
Проверял несколько раз, тенденция похожая, при 200кк элементов считается быстрее traditional_way.
Оставлю на ночь с 300, 400, 500кк, посмотрим, подтвердится ли.
да, в глобальном смысле это понятно, но хотелось бы понять так же, почему расчет при использовании встроенной функции min, которую я бы и использовал при всех подобных задачах, выполняется дольше в несколько раз ?
Странная ситуация, встретив такую задачу на практике, я , зная что min принимает key, захочу воспользоваться именно ей, так как это красивое краткое решение, встроенная функция, а оказывается оно уступит в скорости простому самописному алгоритму в 4 раза ?
Мне так не кажется, реализации найти не смог, но мне думается, что при наличии key lamdba функция применяется к элементу, а потом идет сравнение просто и происходит это за 1 проход.
Teslaman, Не думаю, что вы правы. n - не "Абстрактная штука", а размерность входных данных.
В любом случае, спасибо за комментарий, благодаря вашему псевдокоду я понял, что в первом случае сложность для n=len(scores) и m=len(alice) будет O(n * log n * m) так как сложность sorted O(n * log n), то есть больше чем поиска по индексу, тогда как сложность второго варианта O(m * n)
Это не так. Почему тут будет n^2 ?? Что такое n ? Это длина массива. n^2 был бы если бы был цикл и вложенный цикл по 1 массиву длиной n. А насчет n^3 в первом варианте - первый цикл по alice * index(), который выполняется за O(len(scores))