Доброго времени суток
Мне нужно перекодировать
этот файл
в Windows-1251
Пытался это сделать с помощью встроенный функции sublime но получал ошибку
После нашел
код на python для перекодировки
# -*- coding: utf-8 -*-
# UTF8 to cp1251 and ShiftJIS recoder
# by Chtobi and Nazon, 2016
import codecs
import argparse
from os import path
JAPANESE_CODEPAGE = 'shift_jis'
UTF_CODEPAGE = 'utf-8'
RUS_CODEPAGE = 'cp1251'
def nonrus_handler(e):
if e.object[e.start:e.end] == '~': # UTF-8: 0xEFBD9E -> SHIFT-JIS: 0x8160
japstr_byte = b'\x81\x60'
elif e.object[e.start:e.end] == '-': # UTF-8: 0xEFBC8D -> SHIFT-JIS: 0x817C
japstr_byte = b'\x81\x7c'
else:
japstr_byte = (e.object[e.start:e.end]).encode(JAPANESE_CODEPAGE)
return japstr_byte, e.end
if __name__ == '__main__':
arg_parser = argparse.ArgumentParser(prog="Recode to cp1251 and ShiftJIS",
description="Program to encode UTF8 text file to "
"cp1251 for all cyrillic symbols and ShiftJIS for others. "
"Output file will be inputfilename.s",
usage="recode_to_cp1251_shiftjis.py file_name")
arg_parser.add_argument('file_name', nargs=1, type=argparse.FileType(mode='r', bufsize=-1),
help="Input text file name. Only files coded in UTF8 are allowed.\n")
codecs.register_error('nonrus_handler', nonrus_handler)
input_name = arg_parser.parse_args().file_name[0].name
output_name = path.splitext(input_name)[0] + ".s"
with open(input_name, 'rt', encoding = UTF_CODEPAGE) as input_file:
with open(output_name, 'wb') as output_file:
if input_name.find(u'\xa0') >= 0:
input_name = input_name.replace(u'\xa0', u' ')
elif input_name.find(u'\ufeff') >= 0:
input_name = input_name.replace(u'\ufeff', u'')
for line in input_file:
for char1 in line:
bytes_out = bytes(line, UTF_CODEPAGE)
output_file.write(char1.encode(RUS_CODEPAGE, "nonrus_handler"))
print("Done.")
Он перекодировал файл правда все русские символы превратились в непонятно что
Âðåìÿ òÿíåòñÿ áåñêîíå÷íî äîëãî.@
` Íî â ðåàëüíîì ìèðå íå ðàçäàëîñü è òûñÿ÷íîãî òèêàíüÿ ÷àñîâ.@
` Àðêâåéä ïîäíèìàåò ãîëîâó, è ñìîòðèò íà ìåíÿ òàê, ñëîâíî âèäèò ñîí.\
` – Øèêè, òû âñ¸ íå óõîäèë äîìîé.@ È ÿ ïðèøëà ñþäà, ïîòîìó ÷òî íå ìîãëà îñòàâèòü òåáÿ îäíîãî...@ Õîòü ÿ è ñîáèðàëàñü âîçâðàùàòüñÿ ê ñåáå.@
` Îíà íåìíîãî çàïèíàåòñÿ, íî ãîâîðèò â ñâîåé îáû÷íîé æèçíåðàäîñòíîé ìàíåðå.\
` – Êîíå÷íî ÿ íå óõîäèë.@ Ðàçâå ÿ íå ãîâîðèë ÷òî áóäó äåðæàòü ñâî¸ îáåùàíèå?@ ß âñ¸ åù¸ íèêàê íå ïîìîã òåáå ñåãîäíÿ.@
` – Õâàòèò óæå...@ Òåáå áîëüøå íå íóæíî ýòîãî äåëàòü.@
` – Õâàòèò?.. ×åãî õâàòèò, Àðêâåéä?!..\
` – Ðàçâå íå ÿñíî?@ Ïðîñòî òû ÷åëîâåê, Øèêè, à ÿ âàìïèð.@
` Ó ìåíÿ íå áûëî ïðàâà ïðîñèòü òåáÿ î ïîìîùè.@ ß íå ïîíèìàëà ýòîãî ðàíüøå, è ÿ áû ðàçðóøèëà òåáÿ, åñëè áû çàøëà íåìíîãî äàëüøå.@
` Ïîýòîìó...@
` «...äîñòàòî÷íî», øåï÷åò îíà.\
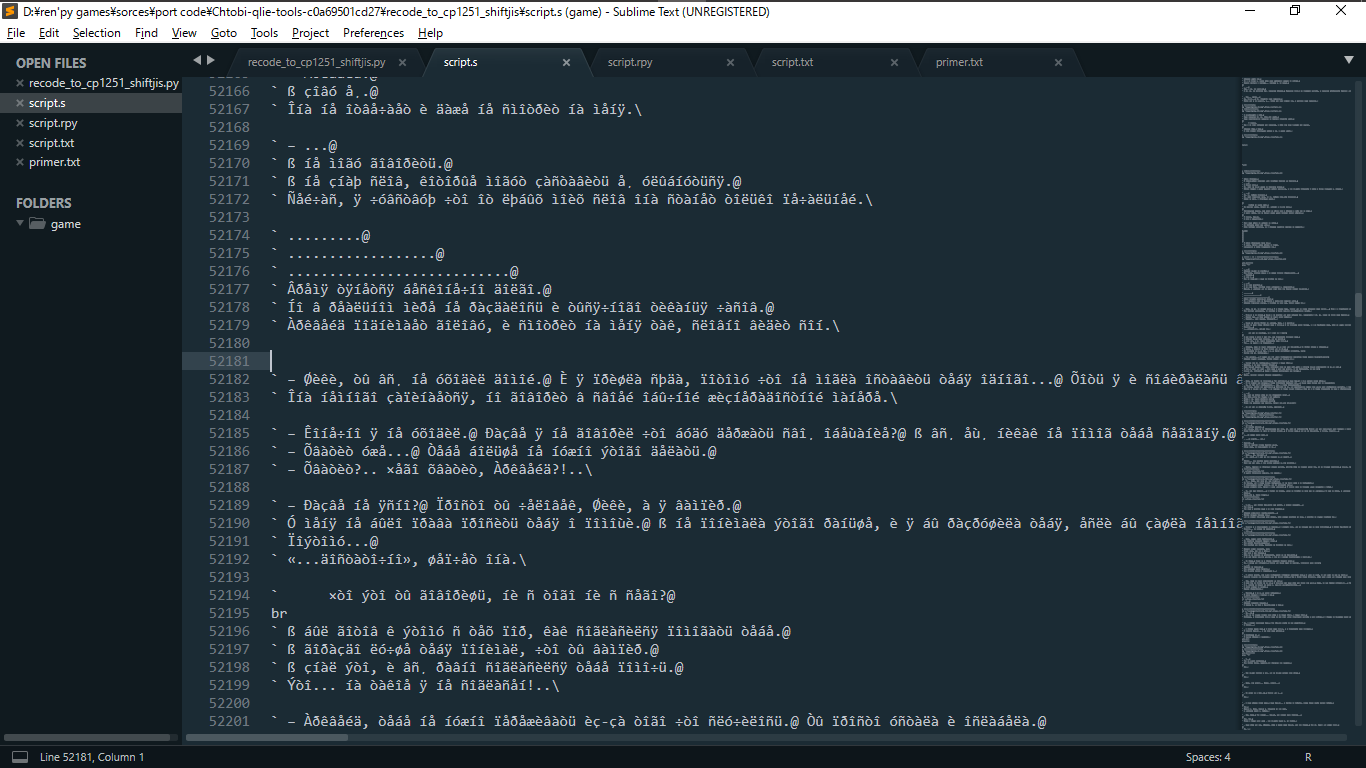
Есть ли способ вернуть русским смволам их изнчалный вид ? или же есть метод который не будить шакалить символы ?
Зарание Спасибо за ответ