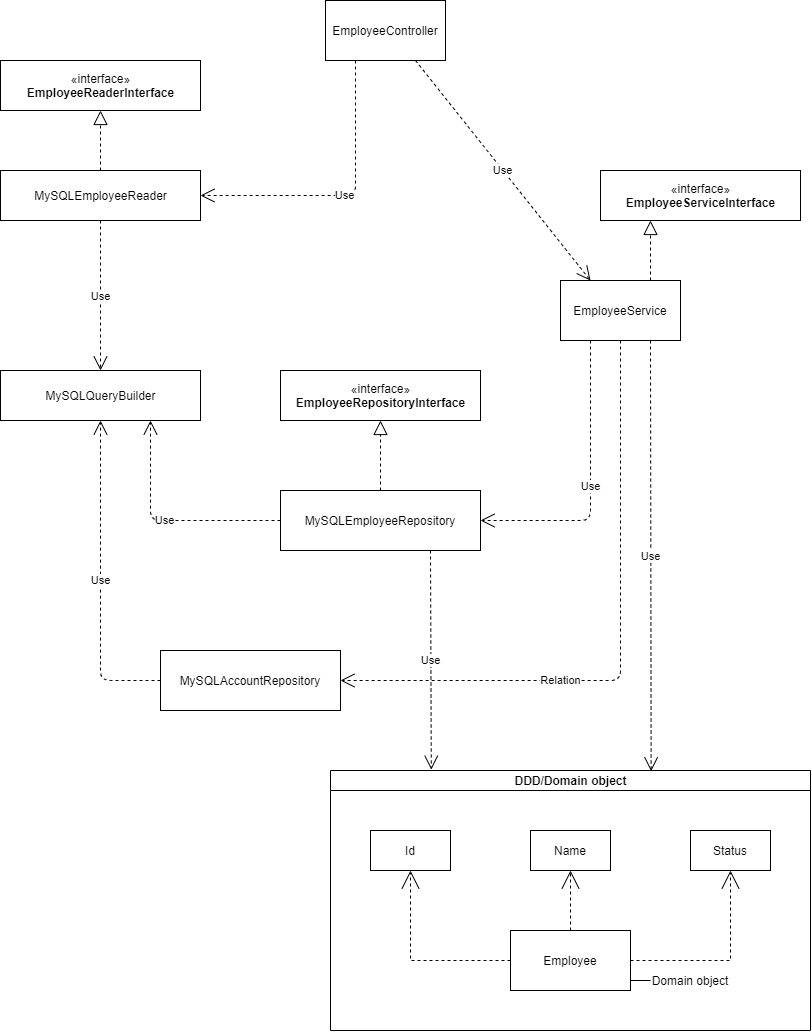
Предметная область — множество всех сущностей и их отношений в рамках контекста.
Например:
В рамках магазина это покупатели, продавцы, товары, цены, скидки, поставщики, процесс продажи, прихода на склад, возврата и т.п.
В рамках дискорда это пользователи, серверы, комнаты, группы, права на доступ, процессы присоединения к серверу, входа в комнату, оплаты nitro, написания текстового сообщения и т.п.
В целом, это всё, что понимает твой менеджер и ничего, что он не понимает. В предметную область не входит, например, то, где именно ты хранишь данные — в mysql, в файлах, получаешь и сохраняешь их по API или хранишь их в redis'е. Но входит абстрактная сущность "хранилище". Она же — интерфейс репозитория. Репозиторий — это паттерн, который скрывает реализацию конкретного хранилища и который оперирует объектами доменной модели — элементами предметной области, как будто они хранятся у тебя в оперативной памяти. Например, у репозитория могут быть методы
users.getByID(1234), users.save(user), users.getByEmail("hello@world")
и т.п. Реализация репозитория определяет, куда именно сохранится этот user или откуда он скачается. В одну таблицу или в несколько. Нормализованные ли будут данные лежать в РСУБД или денормализованные. Именно здесь можно реализовать запись в master, а чтение с реплик. Или энкодинг в msgpack и передачу его по API куда-то. Или по gRPC. Потому что предметная область не должна перегружаться деталями реализации хранилищ.
Про доменную модель:
Словарь (он же хэш, он же ассоциативный массив) — это не доменная модель (хотя в некоторых функциональных языках может быть). Объект ORM — это тоже не доменная модель, хотя много где пытается ей быть. Доменная модель не зависит от конкретных фреймворков, баз данных, оптимизаций этих баз и прочих навязанных технической составляющей сущностей. Чаще всего это обычный класс на языке, на котором пишется код (или struct в случае Golang).
Недавний пример:
У сущности есть теги по категориям:
{"category1": ["foo", "bar"], "cat2": ["foo", "hello", "world"]}
. Их так удобно представлять на уровне предметной области, об этой структуре я могу общаться с заказчиком. Но в монге они сохраняются в виде
['category1%%foo', 'category1%%bar', 'cat2%%foo', 'cat2%%hello', 'cat2world']
, потому что так их легче индексировать и быстрее по ним искать. Но это скрыто в реализации репозитория, доменная область про это ничего не знает. Это даёт сразу много преимуществ:
1. Это очень просто тестировать, без всяких моков. Вместо репозитория с монгой я делаю репозиторий, который хранит сущности в оперативе. Всё, тесты бизнес-логики не зависят от инфраструктуры. А репозиторий монги я тестирую отдельно, мокая запросы в саму монгу или даже не мокая
2. Это облегчает понимание всего продукта. Мозг не пытается составить полную картину, когда запросы в БД перемешаны с логикой, тут же сплиты-джойны строк, какие-то ещё низкоуровневые действия. Мозгу легко ориентироваться в пределах уровня. На уровне репозитория я думаю о том, как сущности хранить и доставать из хранилища, на уровне служб я думаю о том, как сущности взаимодействую и
какие их них нужно извлечь/сохранить, но не
как
3. Рефакторинг очень простой. Даже теоретическая смена БД. Завтра с монги нужно будет перенести одну сущность на постгрес — без проблем. Я напишу один новый репозиторий, не затронув ни строчки кода за его пределами, кроме места, где он создаётся. При этом, остальные сущности могут лежать всё также в монге
Доменные модели бывают богатыми и анемичными (но не бескровными). Оба подхода применяются и, имхо, не является антипаттерном ни один из них. Лично я использую анемичные модели, а всю бизнес-логику храню в службах.

 Сложный
Сложный