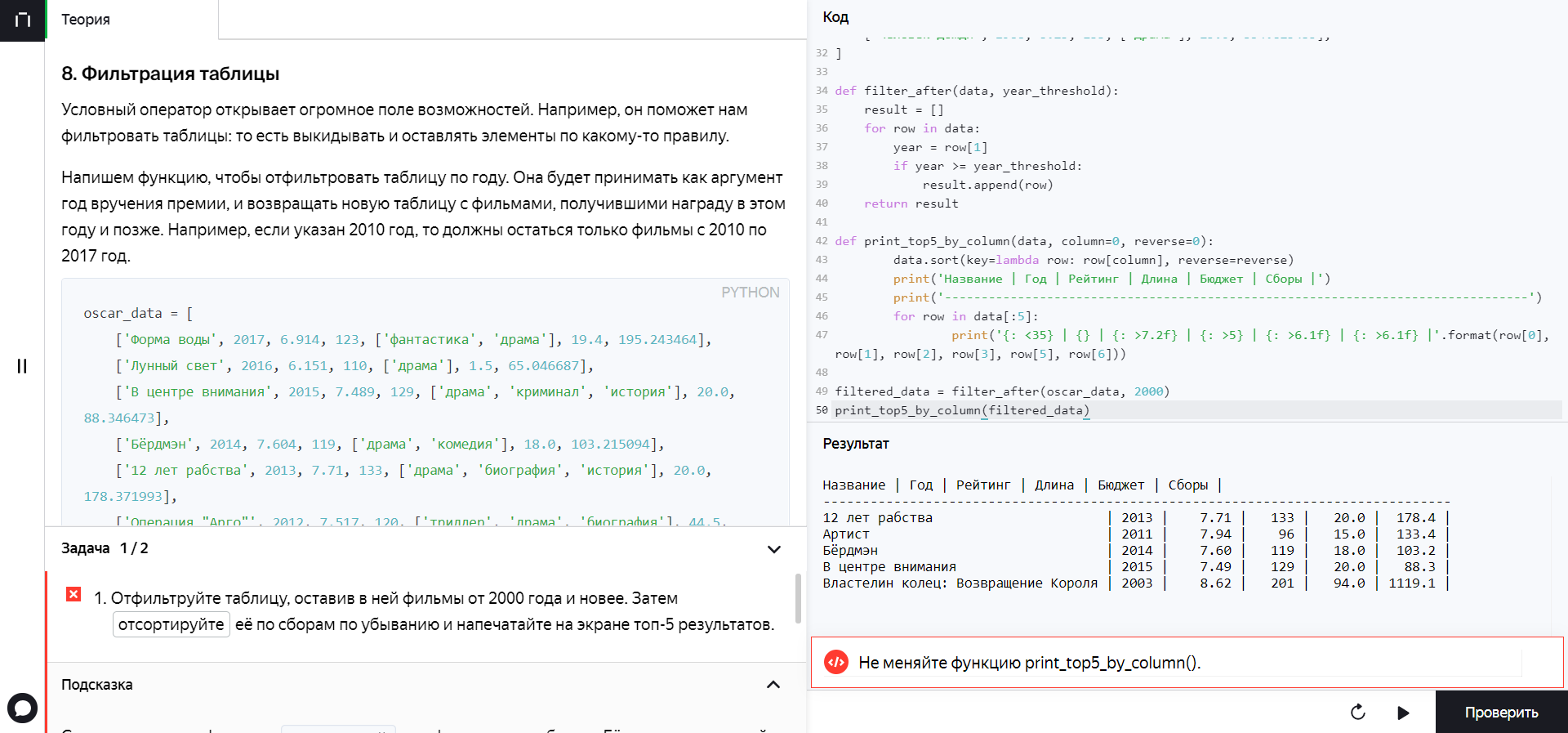
oscar_data = [
['Форма воды', 2017, 6.914, 123, ['фантастика', 'драма'], 19.4, 195.243464],
['Лунный свет', 2016, 6.151, 110, ['драма'], 1.5, 65.046687],
['В центре внимания', 2015, 7.489, 129, ['драма', 'криминал', 'история'], 20.0, 88.346473],
['Бёрдмэн', 2014, 7.604, 119, ['драма', 'комедия'], 18.0, 103.215094],
['12 лет рабства', 2013, 7.71, 133, ['драма', 'биография', 'история'], 20.0, 178.371993],
['Операция "Арго"', 2012, 7.517, 120, ['триллер', 'драма', 'биография'], 44.5, 232.324128],
['Артист', 2011, 7.942, 96, ['драма', 'мелодрама', 'комедия'], 15.0, 133.432856],
['Король говорит!', 2010, 7.977, 118, ['драма', 'биография', 'история'], 15.0, 414.211549],
['Повелитель бури', 2008, 7.298, 126, ['триллер', 'драма', 'военный', 'история'], 15.0, 49.230772],
['Миллионер из трущоб', 2008, 7.724, 120, ['драма', 'мелодрама'], 15.0, 377.910544],
['Старикам тут не место', 2007, 7.726, 122, ['триллер', 'драма', 'криминал'], 25.0, 171.627166],
['Отступники', 2006, 8.456, 151, ['триллер', 'драма', 'криминал'], 90.0, 289.847354],
['Столкновение', 2004, 7.896, 108, ['триллер', 'драма', 'криминал'], 6.5, 98.410061],
['Малышка на миллион', 2004, 8.075, 132, ['драма', 'спорт'], 30.0, 216.763646],
['Властелин колец: Возвращение Короля', 2003, 8.617, 201, ['фэнтези', 'драма', 'приключения'], 94.0, 1119.110941],
['Чикаго', 2002, 7.669, 113, ['мюзикл', 'комедия', 'криминал'], 45.0, 306.776732],
['Игры разума', 2001, 8.557, 135, ['драма', 'биография', 'мелодрама'], 58.0, 313.542341],
['Гладиатор', 2000, 8.585, 155, ['боевик', 'драма', 'приключения'], 103.0, 457.640427],
['Красота по-американски', 1999, 7.965, 122, ['драма'], 15.0, 356.296601],
['Влюбленный Шекспир', 1998, 7.452, 123, ['драма', 'мелодрама', 'комедия', 'история'], 25.0, 289.317794],
['Титаник', 1997, 8.369, 194, ['драма', 'мелодрама'], 200.0, 2185.372302],
['Английский пациент', 1996, 7.849, 155, ['драма', 'мелодрама', 'военный'], 27.0, 231.976425],
['Храброе сердце', 1995, 8.283, 178, ['драма', 'военный', 'биография', 'история'], 72.0, 210.409945],
['Форрест Гамп', 1994, 8.915, 142, ['драма', 'мелодрама'], 55.0, 677.386686],
['Список Шиндлера', 1993, 8.819, 195, ['драма', 'биография', 'история'], 22.0, 321.265768],
['Непрощенный', 1992, 7.858, 131, ['драма', 'вестерн'], 14.4, 159.157447],
['Молчание ягнят', 1990, 8.335, 114, ['триллер', 'криминал', 'детектив', 'драма', 'ужасы'], 19.0, 272.742922],
['Танцующий с волками', 1990, 8.112, 181, ['драма', 'приключения', 'вестерн'], 22.0, 424.208848],
['Шофёр мисс Дэйзи', 1989, 7.645, 99, ['драма'], 7.5, 145.793296],
['Человек дождя', 1988, 8.25, 133, ['драма'], 25.0, 354.825435],
]
def filter_after(data, year_threshold):
result = []
for row in data:
year = row[1]
if year >= year_threshold:
result.append(row)
return result
def print_top5_by_column(data, column, reverse):
data.sort(key=lambda row: row[column], reverse=reverse)
print('Название | Год | Рейтинг | Длина | Бюджет | Сборы |')
print('--------------------------------------------------------------------------------')
for row in data[:5]:
print('{: <35} | {} | {: >7.2f} | {: >5} | {: >6.1f} | {: >6.1f} |'.format(
row[0], row[1], row[2], row[3], row[5], row[6]))
filtered_data = filter_after(oscar_data, 2000)
print_top5_by_column(filtered_data)oscar_data = [
['Форма воды', 2017, 6.914, 123, ['фантастика', 'драма'], 19.4, 195.243464],
['Лунный свет', 2016, 6.151, 110, ['драма'], 1.5, 65.046687],
['В центре внимания', 2015, 7.489, 129, ['драма', 'криминал', 'история'], 20.0, 88.346473],
['Бёрдмэн', 2014, 7.604, 119, ['драма', 'комедия'], 18.0, 103.215094],
['12 лет рабства', 2013, 7.71, 133, ['драма', 'биография', 'история'], 20.0, 178.371993],
['Операция "Арго"', 2012, 7.517, 120, ['триллер', 'драма', 'биография'], 44.5, 232.324128],
['Артист', 2011, 7.942, 96, ['драма', 'мелодрама', 'комедия'], 15.0, 133.432856],
['Король говорит!', 2010, 7.977, 118, ['драма', 'биография', 'история'], 15.0, 414.211549],
['Повелитель бури', 2008, 7.298, 126, ['триллер', 'драма', 'военный', 'история'], 15.0, 49.230772],
['Миллионер из трущоб', 2008, 7.724, 120, ['драма', 'мелодрама'], 15.0, 377.910544],
['Старикам тут не место', 2007, 7.726, 122, ['триллер', 'драма', 'криминал'], 25.0, 171.627166],
['Отступники', 2006, 8.456, 151, ['триллер', 'драма', 'криминал'], 90.0, 289.847354],
['Столкновение', 2004, 7.896, 108, ['триллер', 'драма', 'криминал'], 6.5, 98.410061],
['Малышка на миллион', 2004, 8.075, 132, ['драма', 'спорт'], 30.0, 216.763646],
['Властелин колец: Возвращение Короля', 2003, 8.617, 201, ['фэнтези', 'драма', 'приключения'], 94.0, 1119.110941],
['Чикаго', 2002, 7.669, 113, ['мюзикл', 'комедия', 'криминал'], 45.0, 306.776732],
['Игры разума', 2001, 8.557, 135, ['драма', 'биография', 'мелодрама'], 58.0, 313.542341],
['Гладиатор', 2000, 8.585, 155, ['боевик', 'драма', 'приключения'], 103.0, 457.640427],
['Красота по-американски', 1999, 7.965, 122, ['драма'], 15.0, 356.296601],
['Влюбленный Шекспир', 1998, 7.452, 123, ['драма', 'мелодрама', 'комедия', 'история'], 25.0, 289.317794],
['Титаник', 1997, 8.369, 194, ['драма', 'мелодрама'], 200.0, 2185.372302],
['Английский пациент', 1996, 7.849, 155, ['драма', 'мелодрама', 'военный'], 27.0, 231.976425],
['Храброе сердце', 1995, 8.283, 178, ['драма', 'военный', 'биография', 'история'], 72.0, 210.409945],
['Форрест Гамп', 1994, 8.915, 142, ['драма', 'мелодрама'], 55.0, 677.386686],
['Список Шиндлера', 1993, 8.819, 195, ['драма', 'биография', 'история'], 22.0, 321.265768],
['Непрощенный', 1992, 7.858, 131, ['драма', 'вестерн'], 14.4, 159.157447],
['Молчание ягнят', 1990, 8.335, 114, ['триллер', 'криминал', 'детектив', 'драма', 'ужасы'], 19.0, 272.742922],
['Танцующий с волками', 1990, 8.112, 181, ['драма', 'приключения', 'вестерн'], 22.0, 424.208848],
['Шофёр мисс Дэйзи', 1989, 7.645, 99, ['драма'], 7.5, 145.793296],
['Человек дождя', 1988, 8.25, 133, ['драма'], 25.0, 354.825435],
]
def filter_after(data, year_threshold):
result = []
for row in data:
year = row[1]
if year >= year_threshold:
result.append(row)
return result
def print_top5_by_column(data, column=0, reverse=0):
data.sort(key=lambda row: row[column], reverse=reverse)
print('Название | Год | Рейтинг | Длина | Бюджет | Сборы |')
print('--------------------------------------------------------------------------------')
for row in data[:5]:
print('{: <35} | {} | {: >7.2f} | {: >5} | {: >6.1f} | {: >6.1f} |'.format(row[0], row[1], row[2], row[3], row[5], row[6]))
filtered_data = filter_after(oscar_data, 2000)
print_top5_by_column(filtered_data)