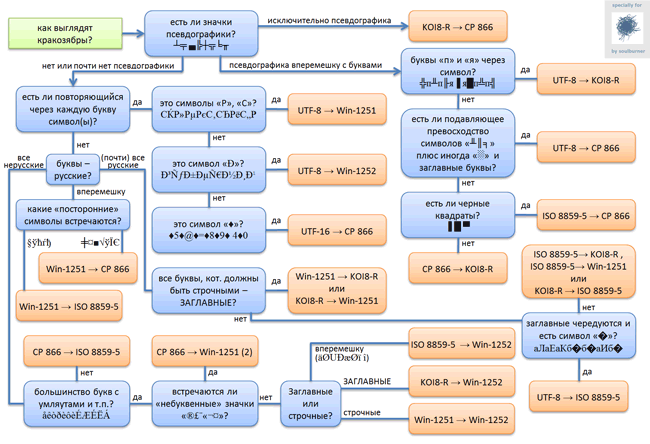
На php собираю новости с сайта. Штук 15 сайтов уже парсятся нормально, сейчас столкнулся с проблемой кодировки текста на исходном сайте.
Получаю заголовки новостей отсюда:
www.tyumen-judo.ru/news
Php мне выдаёт, например: ÐндÑÑÑÑÐ¸Ñ ÑпоÑÑа!
Погуглил - нашёл mb_convert_encoding.
Но прикол в том, что на сайте и так кодировка utf-8! Это прописано в мета. И мой php, через mb_detect_encoding, тоже говорит что это utf-8.
Вот нет идей, почему так отображается и как это пофиксить.
UPD: конвертация кракозябр в CP1252 даёт читаемый текст! Но php (и все декодеры) по-прежнему определяет исходную кодировку как utf-8. А мне, блин, надо чтобы универсальный алгоритм для парсинга текста был. То есть, для всех сайтов я в БД храню атрибут или селектор, по которому он на сайте ищет нужный элемент и вытаскивает из него данные. И все сайты в utf-8, вроде. Я бы написал условие, при котором нужно конвертить текст, но как тут поступить - хз.