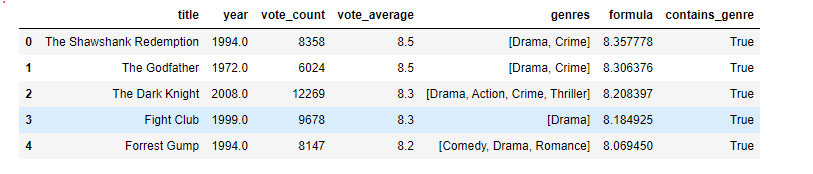
rank['contains_genre'] = [any( y in x for y in genres) for x in rank.genres]
genres-это входные данныеgenres=['Drama', 'Crime']
b=['Drama', 'Action', 'Crime', 'Thriller']
c=[any( y in x for y in genres) for x in b]с
[True, False, True, False]c=[all( y in x for y in genres) for x in b]
вообще
[False, False, False, False]in? Что-то явно лишнее - либо оператор, либо один из циклов. А то проверяется наличие строки в строке, а не в наборе строк.# хотим отобрать фильмы с такими жанрами - хотя бы одним, но не обязательно всеми сразу
genres_to_look_for = ['Drama', 'Crime']
# вот набор фильмов и их жанров
movies_and_genres = {
1: ['Drama', 'Action', 'Crime', 'Thriller'],
2: ['Drama'],
3: ['Drama'],
4: ['Comedy']}
# для каждого фильма проверяем наличие у него искомых жанров (хотя бы одного)
# если any заменить на all, то будет проверяться одновременное наличие всех искомых жанров
movies_filtered = {
movie: any((genre in genres) for genre in genres_to_look_for)
for movie, genres in movies_and_genres.items()
}
print(movies_filtered){1: True, 2: True, 3: True, 4: False} - прямо то, что надо, согласно моему пониманию задачи - в первых трех есть жанр drama, последний в пролете. А если использовать all, то получится {1: True, 2: False, 3: False, 4: False}.
Сложный
Средний
Простой
Простой