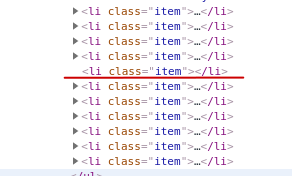
Есть код:
responce = requests.get('
https://101hotels.com/recreation/russia/sankt-pete...').text
html = BS(responce, 'html.parser')
items = html.find_all('li', class_='item')
d = []
for item in items:
d.append({
'title': item.find('div', class_='item-name').text,
'address': item.find('span', class_='item-address'),
'p': item.find('div', class_='item-description')
})
print (d)
Когда нажимаю выполнить, пишет ошибку: 'title': item.find('div', class_='item-name').text, AttributeError: 'NoneType' object has no attribute 'text', хотя в классе есть текст, но он почему-то его не видит, как это исправить?