
import requests
from bs4 import BeautifulSoup
from lxml import html
ses = requests.Session()
page = ses.get("http://tiwar.ru/?sign_in=1")
data = {"login": "vaseaxxx", "pass": "vaseaxxx"}
auth = ses.post("http://tiwar.ru", data=data)
for i in range(1, 100):
html_text = ses.get("http://tiwar.ru/rating/sumstat/1(номер страницы от 1 до 100 все подряд)").text # Цифра в конец должно меняться до 100
soup = BeautifulSoup(html_text, 'html.parser')
names = soup.find_all('a', {"class": "block_zero"})
for name in names:
open("tiwar.txt", "a").write(name.contents[0].strip() + "\n")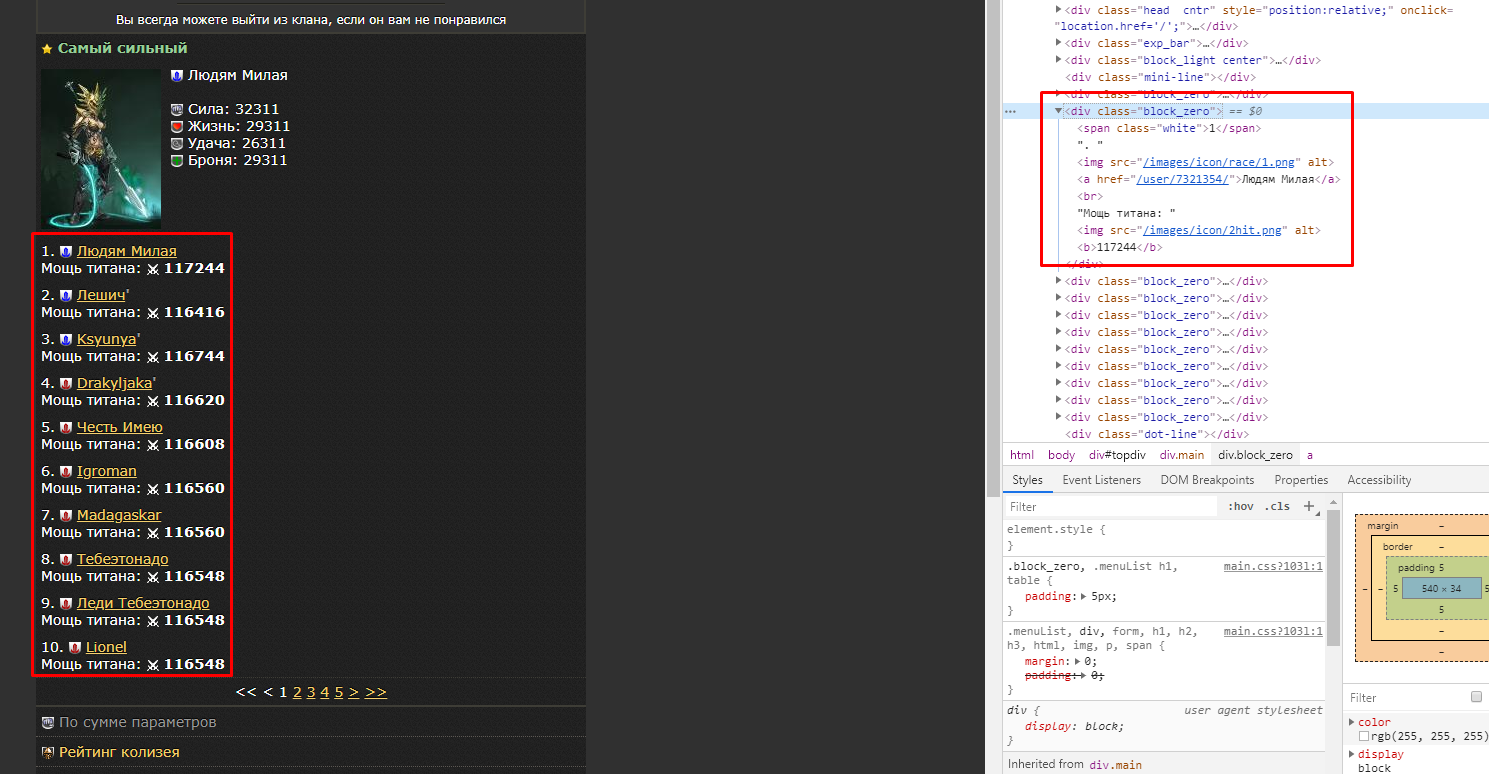

for i in range(1,100):
tiwar = open('tiwar.txt','a')
html_text = ses.get(f"http://tiwar.ru/rating/sumstat/{i}").text
soup = BeautifulSoup(html_text, 'html.parser')
names = soup.find_all('div',class_='block_zero')
for name in names[:-2]:
nick = name.a.text
print(nick)
tiwar.write(nick+'\n')
tiwar.close()