Здравствуйте!
Поставил для себя
цель: написать программу, которая бы скачивала видео все/выборочно с какого-либо (поиск осуществляется по логину) аккаунта tikitok.
Данную задачу я разделил на подзадачи. И с одной из подзадач (а она самая важная) возникла проблема.
Не получается программно загрузить контент сайта. Например, я взял случайный популярный аккаунт
https://www.tiktok.com/@egorkreed . Сначала пытался с помощью библиотеки
requests в связке с
bs4 получить html страницу. Понял, что этот способ не подходит. Страница генерируется динамически. Решил использовать библиотеку
Selenium.
Код для подзадачи:
spoilerСейчас я максимально упростил код
import time
from selenium import webdriver
URL = 'https://www.tiktok.com/@egorkreed'
def get_html(url):
driver = webdriver.Chrome()
driver.get(url)
get_html(URL)
Данный код открывает страницу:
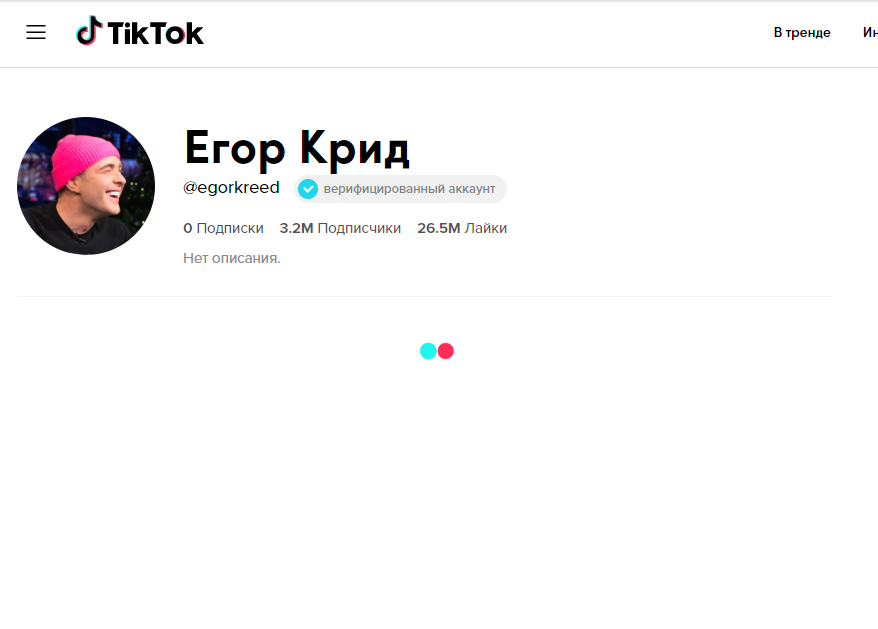 Результат
Результат: Бесконечная попытка прогрузки видео.
Но, если я перейду по той же ссылке
через браузер вручную, то результат будет следующим:

Не понимаю в чём проблема.
Вопрос:
Как грамотно получить код html страницы с помощью Selenium, чтобы контент (клипы) отображались?
P.S.
пробовал использовать адаптированный под мою программу код из примера документации с ожиданием
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
Какое бы время ожидания (10, 50, 100...) я не ставил, результатом программы является исключение. Нужный элемент не найден.


