Есть алгоритм перебора таблицы dataframe. Его смысл — обойти все строки и к первой строке добавить все подходящие строки, сами строки занулить, а подходящими строками считаются строки, ячейки которого в столбце "округ" одинаковые
dopIdx = 0
for row in dataFr['Округ']:
if (dopIdx + 1) == len(dataFr['Округ']):
break
if row == dataFr['Округ'][dopIdx + 1]:
dopdopIdx = dopIdx + 1
while row == dataFr['Округ'][dopdopIdx]:
if dopdopIdx == (len(dataFr['Округ']) - 1):
break
for stolb in dataFr:
if stolb != 'Округ':
dataFr[stolb][dopIdx] = int(dataFr[stolb][dopIdx]) + int(dataFr[stolb][dopdopIdx])
dataFr[stolb][dopdopIdx] = 0
dopdopIdx += 1
dopIdx += 1
dataFr.to_csv(r'C:\Users\rybak\Desktop\OSPanel\domains\pyVOTE\temp_map111.csv', index=False)
ПО итогу получается вот такой csv:
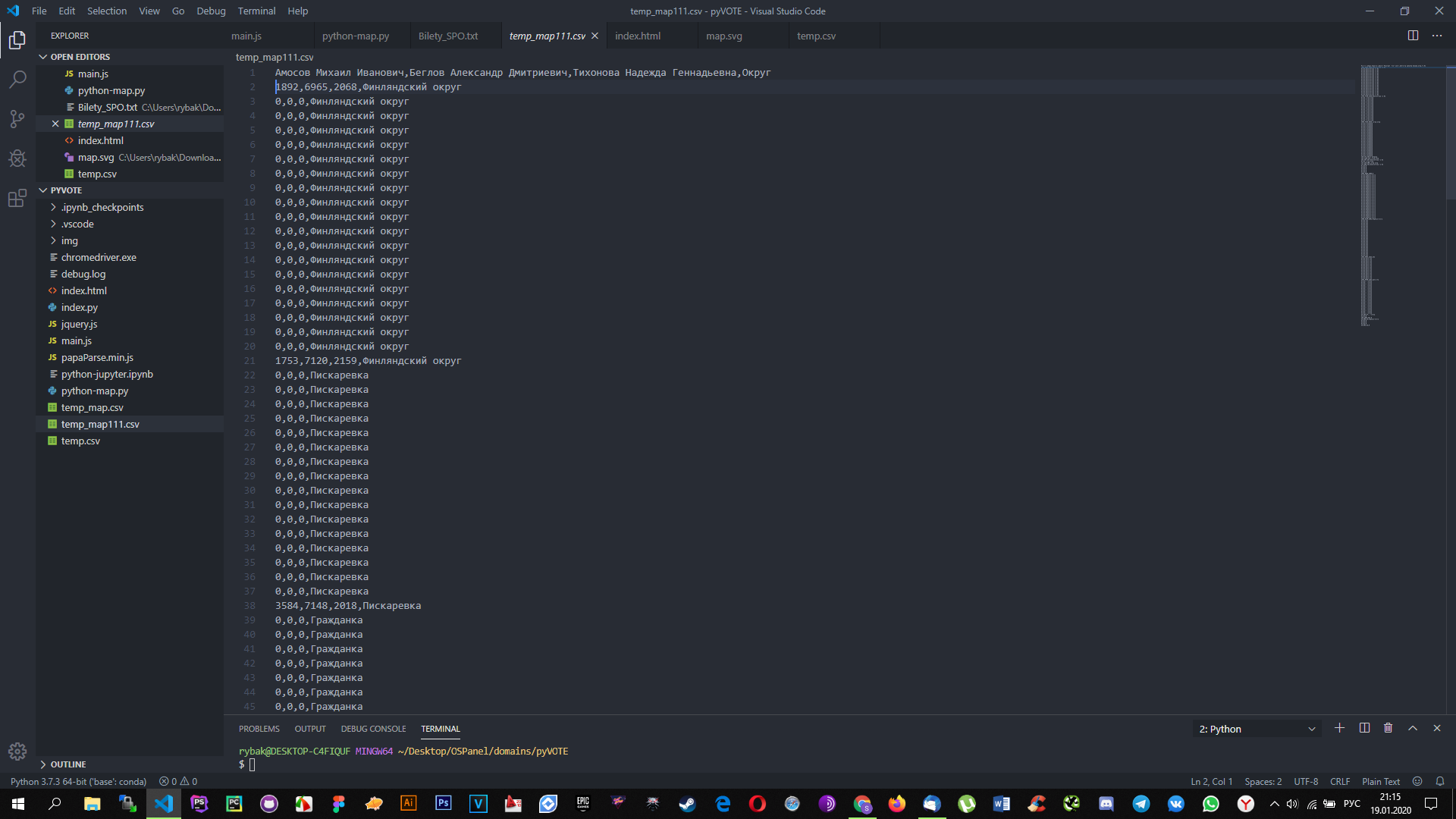
Как можно заметить, начиная со второго округа сумма записывается предыдущую строку.
Внимание, вопрос: где косяк???
Заранее спасибо!!!

