Столкнулся с такой проблемой - есть удаленная БД SQL Server 2012, в которой есть функций, которые возвращают данных.
Приложение развернуто в виртуалке (ubuntu 18.04), подключение настроено через ODBC драйвер 17й версии (т.к. со встроенным драйвером не удалось "договориться"):
user@vm:~$ odbcinst -j
unixODBC 2.3.7
DRIVERS............: /etc/odbcinst.ini
SYSTEM DATA SOURCES: /etc/odbc.ini
FILE DATA SOURCES..: /etc/ODBCDataSources
USER DATA SOURCES..: /home/user/.odbc.ini
SQLULEN Size.......: 8
SQLLEN Size........: 8
SQLSETPOSIROW Size.: 8
посылаю в консоли sqlcmd запрос
SELECT fld FROM foo.fnBar(123, 'username');
Получаю ожидаемый тип данных (кириллическая строка):

Но когда посылаю этот же запрос через DB::select() получаю результат:

Через tinker тоже самое. Кодировка определяется как UTF-8, в бд данные в UTF-8 (так меня уверяют по крайней мере, к самой БД доступа нет, с выборками и просмотрами таблиц тоже самое - только набор функций и хранимок)
Если привести "насильно" к UTF-8 (mb_convert_encoding) получается результат получше:
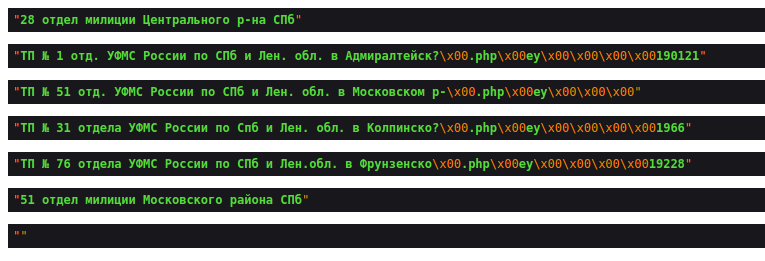
Но остается хвост, который никак не привести к нормальному виду, да и видно, что там мусор по сути а не те данные, что в БД. Есть подозрение, что где-то происходит обрезка строки по количеству бит или что-то типа того, потому как все битые строки длинной не более 57-59 символов, а те, что короче отображаются нормально.
Явное указание кодировки при подключении не спасает ситуацию. Если при подключении передать параметр AutoTranslate = no, то вместо кириллицы возвращаются знаки вопроса, но по количеству символов видно что строка полная и не обрезана, левых hex-кодов нет.:

Если не конвертировать в UTF-8:

вопрос в том, как это дело побороть?


 Средний
Средний

