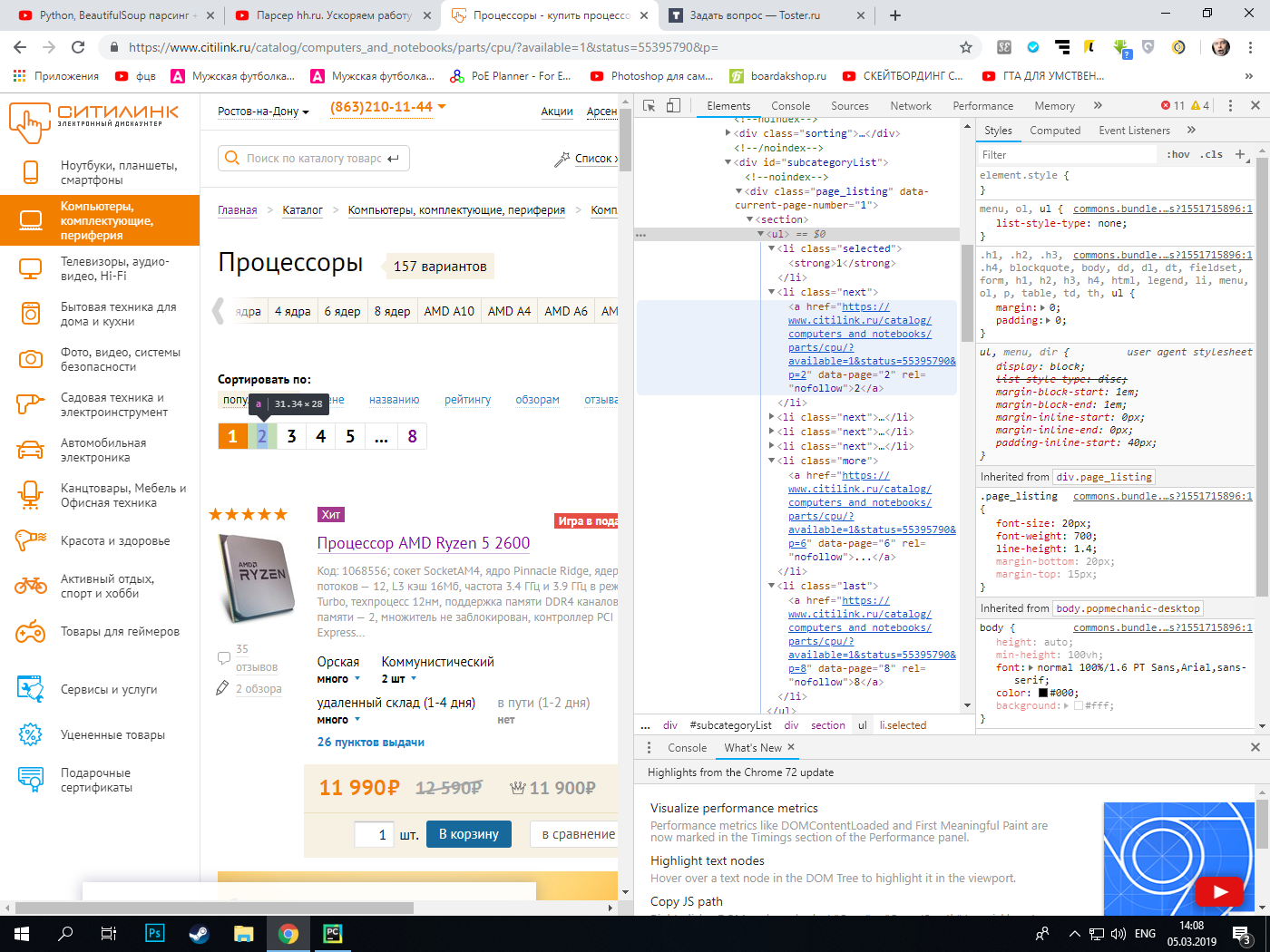
Есть сайт, на котором есть секция с классом page_listing. Нужно из этой секции выудить ссылки, которые находятся в списке с разными классами. У всех ссылок на сайте есть одинаковый атрибут rel="nofollow", так что по этому атрибуту нельзя спарсить данные с многих страниц. Парсер спокойно парсит первую страницу.
import requests
from bs4 import BeautifulSoup as bs
import csv
headers = {'accept' : '*/*', 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.119 Safari/537.36'}
base_url = 'https://www.citilink.ru/catalog/computers_and_notebooks/parts/cpu/?available=1&status=55395790&p=1'
def find_content(base_url, headers):
urls = []
urls.append(base_url)
session = requests.Session()
request = session.get(base_url, headers=headers)
if request.status_code == 200:
request = session.get(base_url, headers=headers)
soup = bs(request.content, 'lxml')
try:
pagination = soup.findAll('a', attrs={'rel' : 'nofollow'})
count = int(pagintaion[-1].text)
except:
pass
for url in urls:
request = session.get(url, headers=headers)
soup = bs(request.content, 'lxml')
divs = soup.findAll('div', attrs={'class' : 'subcategory-product-item'})
for div in divs:
title = div.find('a', attrs={'class' : 'ddl_product_link'}).text
href = div.find('a', attrs={'class' : 'ddl_product_link'})['href']
about = div.find('p', attrs={'class' : 'short_description'}).text
stand_price = div.find('span', attrs={'class' : 'subcategory-product-item__price_standart'}).text
try:
special_price = div.find('span', attrs={'class' : 'subcategory-product-item__price_special'}).text
except:
special_price = '-'
pass
all = title + '\n' + href + '\n' + about + '\n' + 'Стандартная цена: ' + stand_price + '\n' + 'Специальная цена: ' + str(special_price) + '\n\n\n\n'
print(all)
#for i in pagination:
# print(i)
find_content(base_url, headers)