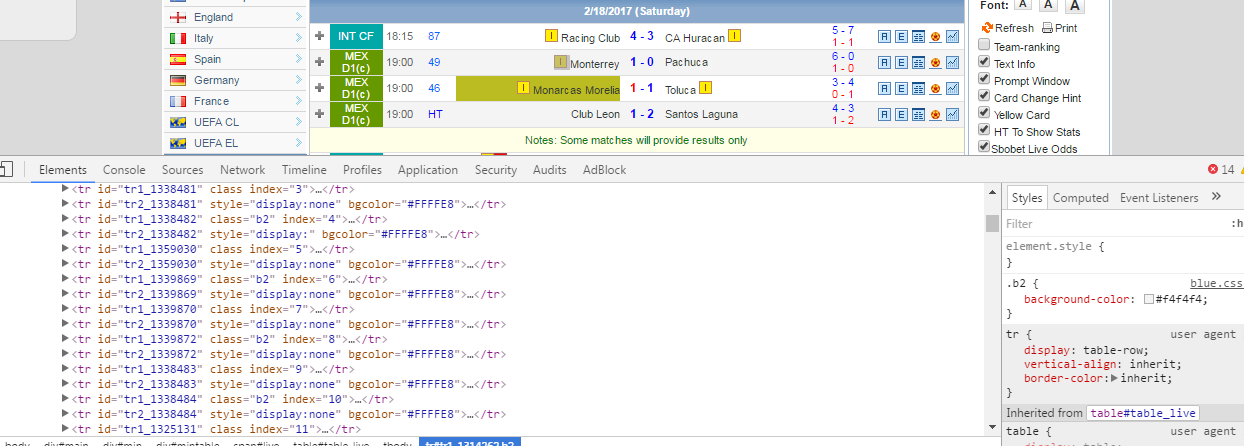
Приветствую. Изучаю web-scraping совсем недавно и не могу победить одну проблемку: есть сайт
www.nowgoal.net . Я хочу получить список всех матчей с главной страницы. Каждый матч имеет свой id (на скрине видно "tr1_id")
,
но я никак не могу извлечь его. Использую BeautifulSoup. Понимаю, что нужно как-то работать с таблицей "table_live", но как мне до нее "добраться"? Простой метод, типа:
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
def main():
html = urlopen("http://www.nowgoal.net/")
soup = BeautifulSoup(html, 'lxml')
res = soup.find('table', id=re.compile("table_live"))
print(res)
if __name__ == "__main__":
main()
не работает (у меня). Направьте меня в нужную сторону, плиз ))



