Пространное вступление
Я пока только начинаются разбираться с возможностями написания кода для GPU и в процессе чтения понял, что два главных ботлнека при работе с GPU это пересылка данных с CPU на видеоустройство и ветвления в коде кернелов, причём главный простой при ветвлениях происходит в варпах, когда один из потоков варпа выполняет ветвление, а остальные ждут прохождения соответствующей ветки кода.
Допустим, есть задача трассировки лучей. Каждый луч может отражаться и преломляться, порождая новые лучи. Происходит это при пересечении луча и поверхности - то есть, с ветвлением кода. Выполнение обработки отражённых и преломлённых лучей можно выполнять запуская рекурсивно функцию трассировки для новых лучей. Но это будет означать простой других потоков пока данный выполняется, и так для каждого из потоков в варпе. Выходит очень плохой для GPU, неоднородный код.
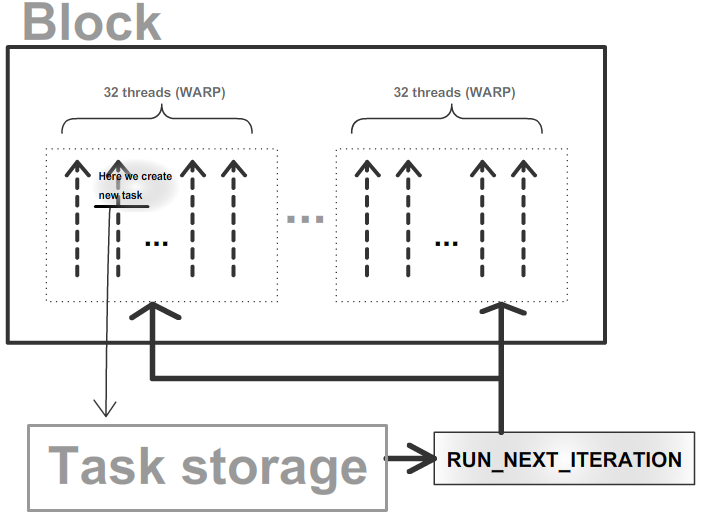
Исходя из этого подумал, что, возможно, было бы полезно написать что-то вроде исполняющегося прямо на GPU task-manager-а для выполнения подобных итеративных действий. С его помощью в местах просчёта лучей вместо полного алгоритма (как в примере - трассировки лучей) можно просто сохранить данные для выполнения трассировки нового луча, а трассировку выполнить когда обработаются все лучи текущей итерации (см. картинку).
Вопрос, как я понимаю, сводится к следующему: нет ли какой-то возможности выполнить повторный запуск потоков на device-устройстве по окончанию текущего исполнения всех потоков без пересылки данных на host-устройство?

 Простой
Простой
 Простой
Простой
 Сложный
Сложный




