Я не совсем уверен что правильно подошел к проблеме, но сутки гугления не дали никаких результатов. Посему хотелось бы услышать реальные мнения.
Итак, имеен парсер XLSX в HTML. Парсер был написан мной на пыхе, он примитивно прост и ошибок в нем точно нет (проверено и перепроверено овер 9999 раз).
С одной стороны вкатываем xlsx с другой выходит готовая html разметка. Ничего сверхъестественного. Но вот в чем загвоздка, если начинать разбивать страницу (массив) по количеству строк и сохранять в файлы, то эти самые html файлы прогрессивно возрастают в размерах.
Вход: xls размером ~1000 строк и весом 605Кб
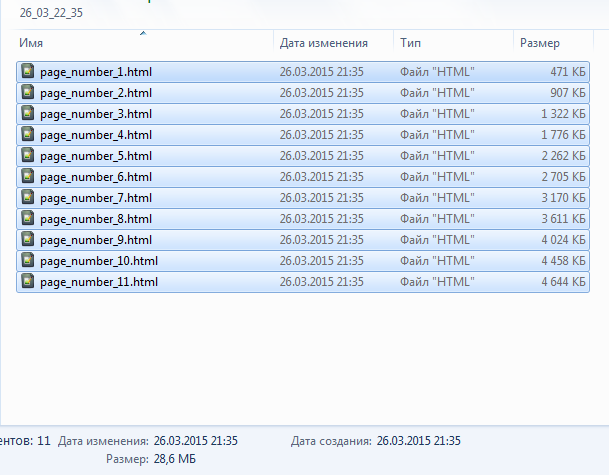
Выхлоп_1 (разбиение по 100строк): 10 HTML файлов весом 28Мб.
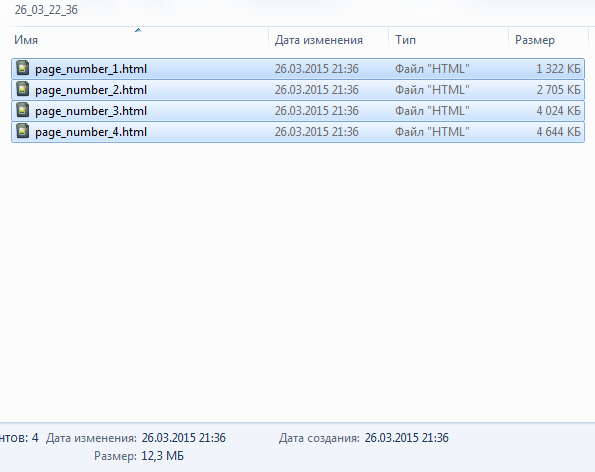
Выхлоп_2 (разбиение по 300строк): 4 HTML файла весом 12Мб.
Соответственно если понадобиться разбить по 200 строк файл с 5000, то там получится не много не мало около 400Мб.
Если делать дамп массива (с разбиением по 300строк), то все сходится - 4 массива с 100 вложенными массивами. Повторений нет, в файлах повторений также нет. Так почему размер так возрастает?
Выхлоп_1
Выхлоп_2





 Средний
Средний

