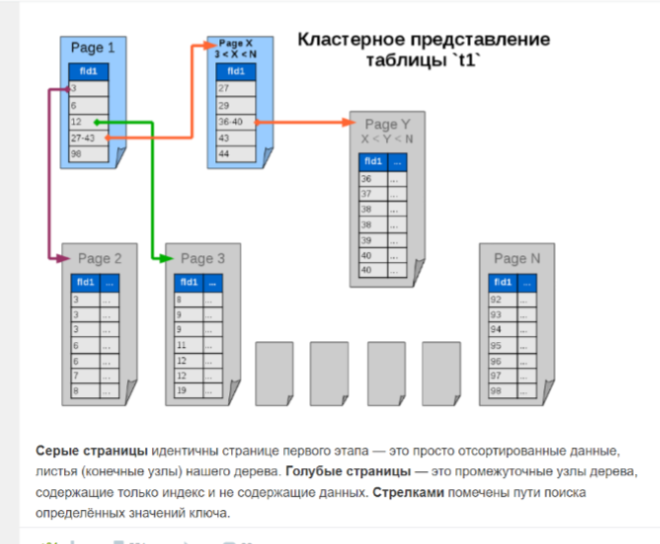
Кластерный индекс... это на самом деле понятие крайне виртуальное.
Что такое обычный некластерный индекс? берём выражение индекса, считаем его значение для каждой записи,
сортируем и пишем на диск. Получаем отдельную структуру, в которой выражение индекса сортировано. Когда потребуется искать заданное значение этого выражения, мы вместо просмотра от записи к записи сразу половинным делением быстренько найдём нужное значение, возьмём из него уникальный идентификатор записи, и обратимся за записью. Если в таблице 1000 записей, то для поиска заданного значения без индекса нам в среднем пришлось бы просмотреть 500 записей, а с индексом - всего 10.
Теперь что такое кластерный индекс... сначала почти то же. Берём выражение индекса, считаем его значение для каждой записи,
сортируем и... а вот теперь не записываем по порядку эти значения с номерами соответствующих записей в отдельную структуру, а сами записи располагаем в этом порядке. Теперь, когда потребуется искать заданное значение этого выражения, мы вместо просмотра от записи к записи, как это было, когда записи не сортированы, сразу половинным делением быстренько найдём нужное значение. Но нам уже не надо получать номер записи и обращаться за ней - мы нашли саму нужную запись.
В MySQL (точнее, в используемом по умолчанию движке InnoDB) первичный индекс, во-первых, существует ВСЕГДА, во-вторых, определяется так (в статье, на которую дали ссылку, имеются неточности в пункте 2):
- Если первичный ключ задан явно, то его выражение является также и выражением кластерного индекса. Или иначе - первичный ключ и есть кластерный индекс.
- Если первичный ключ явно не задан, но в таблице имеется индекс, отвечающий всем следующим требованиям:
- является уникальным
- не является функциональным, в т.ч. не использует в выражении вычисляемые поля
- не использует в выражении поля, которые определены как допускающие значение NULL
то именно такой индекс используется в качестве первичного. А если таких индексов несколько, то используется первый по тексту запроса на создание таблицы
- Если не имеется ни того, ни другого - генерируется синтетический скрытый 6-байтовый номер записи, который и используется как первичный ключ. Следует отметить, что штатных способов доступа к этому значению не существует.
Выглядит так, как будто это просто физическая сортировка данных по индексируемому полю.
Фактически - именно так.
Создаётся ли отдельная таблица или просто упорядочивается хранение существующих данных?
Не создаётся. Но при изменении первичного индекса таблица полностью пересоздаётся с новым физическим порядком записей.
Если данные упорядочиваются этим индексом, допустим по ID, то почему при select без сортировки данные могут возвращаться в произвольном порядке, а не отсортированные по ID по-умолчанию?
Если не задан явно ORDER BY, сервер имеет право вернуть записи в любом порядке, как ему удобнее. В большинстве случаев, но не всегда, он будет возвращать записи в порядке чтения с диска...
Представь такой (на самом деле невозможный, но не суть) случай - ты запросил таблицу. Вторая половина её ещё лежит в кэше, а первая уже выдавлена оттуда данными другой таблицы, нужными для выполнения запроса. Конечно, наиболее оптимальным будет начать передачу данных клиенту с этих записей, а пока они передаются, подчитать остальные, и передать их позже. Вот тебе порядок-то и поломался...
===
PS. Кстати, правило выбора индекса, который будет использоваться в качестве кластерного, имеет неприятный побочный эффект. Если у некоторых полей, входящих в какие-то индексы, изменяется свойство NULLability, то это может привести к изменению того, какой из имеющихся индексов станет использоваться в качестве первичного по пункту 2. В результате мы получим невозможность использования INSTANT / INPLACE методов, и будет использован длинный COPY. Впрочем, ситуация такая крайне редка.