
from bs4 import BeautifulSoup
import requests
url = requests.get('https://www.eldorado.ru/?utm_source=yandex&utm_medium=organic&utm_campaign=yandex&utm_referrer=yandex')
headers = {
"Accept": "*/*",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36"
}
req = requests.get(url, headers=headers)
src = req.text
print(src)
При парсинге выдает ошибку 503. В чем может проблема?
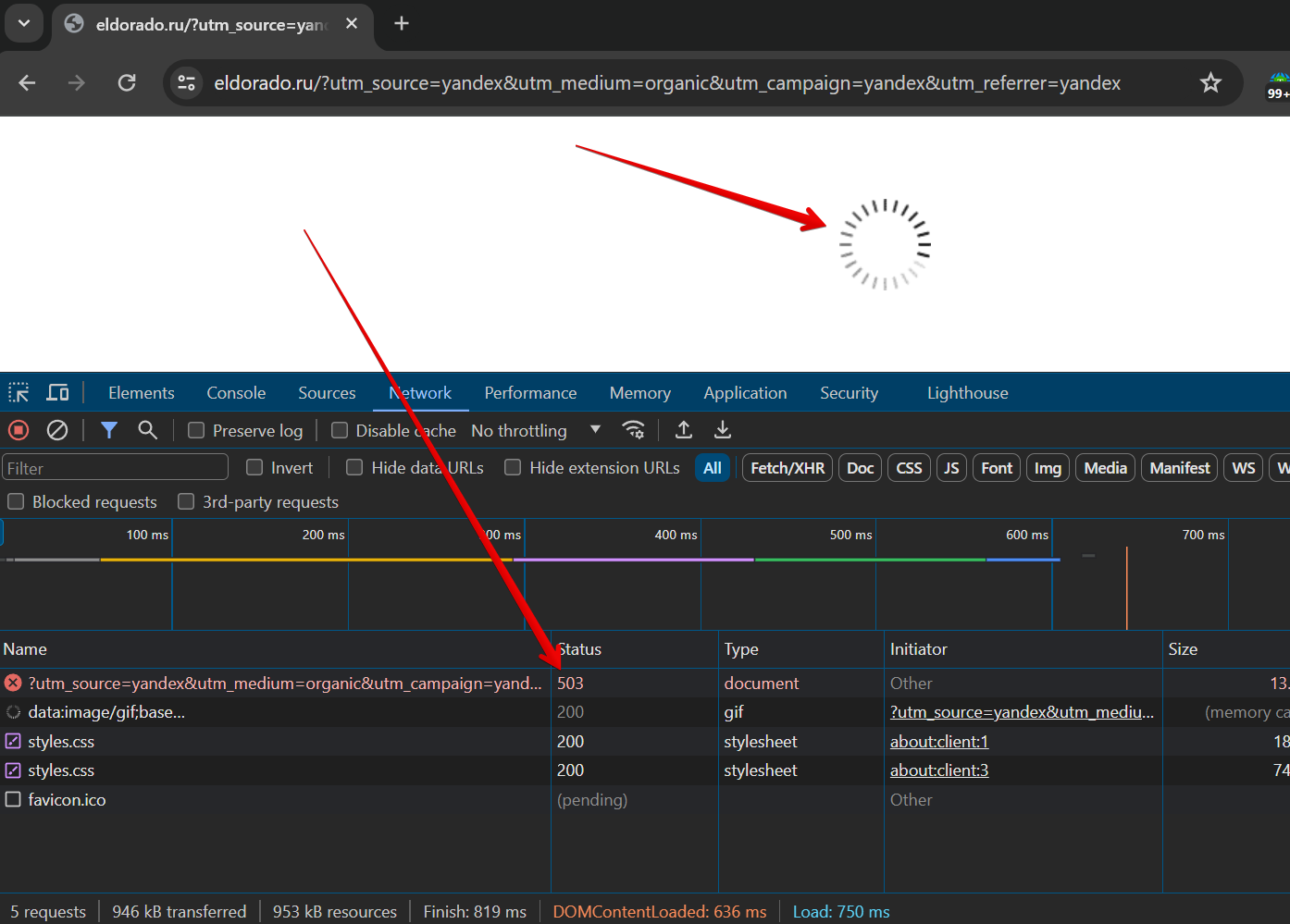
Буду рад, если распишите более подробно, как обходить данную ошибку.
Я сильно сомневаюсь, что этот сайт без антибот защиты
Простой
Простой
Простой