У меня есть следующие сущности:
- документ, целью которого есть просто групировка связанных грузов (например, они все принадлежат одному клиенту);
- грузы;
- документ о перемещении груза.
На данный момент схема устроена таким образом, что каждый груз имеет свои собственные атрибуты.

Необходимо реализовать нововведение, которое приведет к уменьшению дублирования данных, которое происходит в результате того, что в пределах одного группирующего документа существуют почти идентичные грузы (с одинаковыми габаритами и весами), которые отличаются только ID.
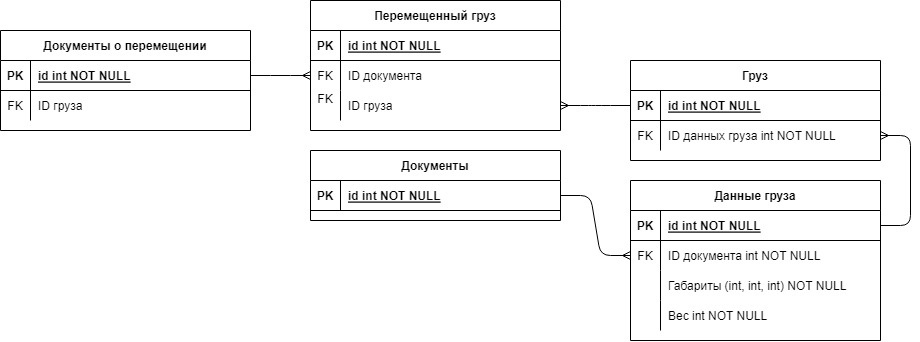
Пока что есть 2 варианта реализации. Первый – разделить таблицу грузов так, что в одной таблице будут храниться атрибуты груза (габариты и вес), а в другой – экземпляры грузов.
Второй – ввести дополнительную колонку "Количество" прямиком в таблицу грузов, но тогда придется добавить колонку "Порядоковый номер груза" в таблицу "Документ о перемещении", чтобы знать какой именно груз записан в документ.
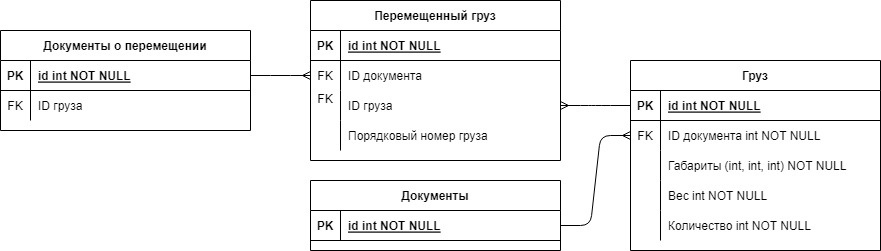
Первый вариант мне нравится больше (тем, что он более удобный), но как минус при выборке данных придется делать лишний JOIN (а это лишняя нагрузка, но, наверное, не большая). Проект учебный, поэтому это не критично, но хочется узнать как лучше было бы сделать в настоящем приложении, а также стоит ли вообще внедрять эту функцию, если учесть, что грузы с дублирующимися данными встречаются редко.


 Простой
Простой



