Очень прошу помочь. Перечитал кучу решений в интернете, пока ничто не оказалось полезным. Не могу понять как поправить эту проблему.
Причем, если открывать тот-же файл Libre Office-ом, то все выглядит как должно...
Для примера, прикладываю скриншоты:
так должно
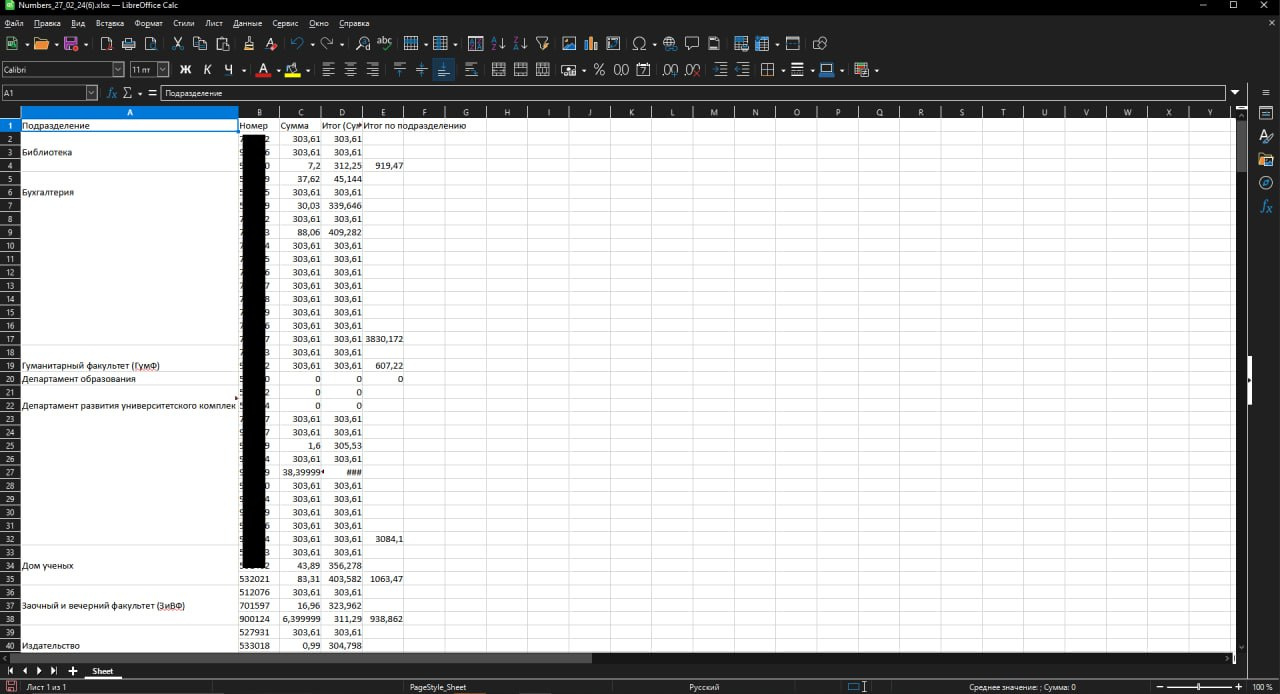
.
Так выходит с excel:
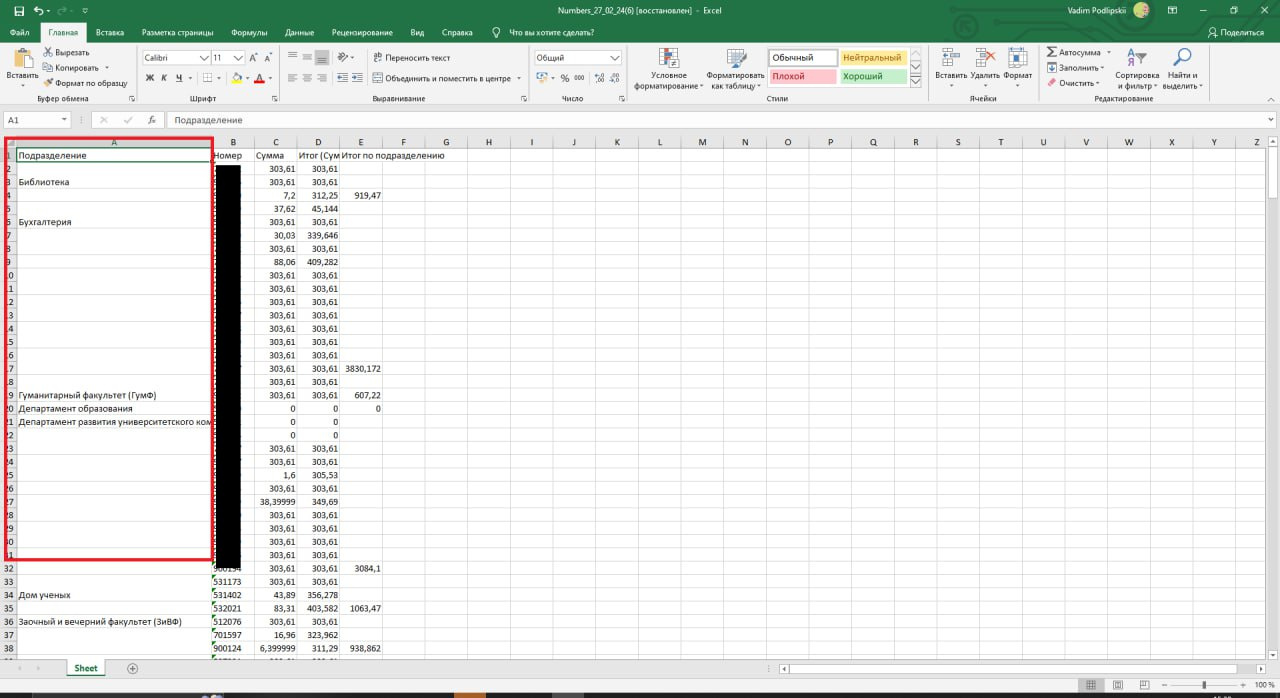
.
Вот какие ошибки вылетают в процессе открытия файла:
1)

2)

На всякий случай приложу функцию формирования отчета:
def export_excel(request):
response = HttpResponse(content_type='application/vnd.ms-excel')
response['Content-Disposition'] = ("attachment; filename=Numbers_" + str(datetime.datetime.now().strftime("%d/%m/%y")) + '.xlsx')
workbook = openpyxl.Workbook()
sheet = workbook.active
headers = ('Подразделение',
'Номер',
'Сумма',
'Итог (Сумма+ндс+абон.плата)',
'Итог по подразделению')
rows_parser = ReportFilter(request.GET, queryset=Parser.objects.all().values_list(
'attachment__attachment', 'number', 'pay', 'result'
)).qs
rows_numbers = ReportFilterNumbers(request.GET, queryset=Numbers.objects.filter(is_enabled=True).values_list(
'attachment__attachment', 'number'
)).qs
res = 0
temp = []
subFee = float(str(SubscriptionFee.objects.get(pk=1)))
for item1 in rows_parser:
temp.append(item1)
res += item1[3]
for item2 in rows_numbers:
if Parser.objects.filter(number=item2[1]):
None
else:
if Numbers.objects.filter(number=item2[1], cf=True):
item2 = list(item2)
item2.extend([0, 0])
res += item2[3]
item2 = tuple(item2)
temp.append(item2)
else:
item2 = list(item2)
item2.extend([subFee, subFee])
res += item2[3]
item2 = tuple(item2)
temp.append(item2)
temp.sort()
itog = 0
for row in range(len(temp)):
itog += temp[row][3]
temp.insert(0, headers)
temp = tuple(temp)
current_value = temp[1][0]
start_row_index = 1
now3 = 0
sheet.append(headers)
for row_index in range(1, len(temp)):
cell_value = temp[row_index][0]
if cell_value != current_value:
sheet.append(temp[row_index])
sheet.cell(row=row_index, column=5).value = now3
now3 = temp[row_index][3]
start_row_index = row_index
current_value = cell_value
elif cell_value == current_value:
now3 += temp[row_index][3]
sheet.append(temp[row_index])
sheet.merge_cells(start_row=start_row_index + 1, start_column=1, end_row=row_index + 1, end_column=1)
start_row_index = row_index
current_value = cell_value
sheet.cell(row=row_index + 1, column=5).value = now3
sheet.cell(row=row_index + 2, column=3).value = 'ОБЩИЙ ИТОГ:'
sheet.cell(row=row_index + 2, column=4).value = itog
workbook.save(response)
return response



