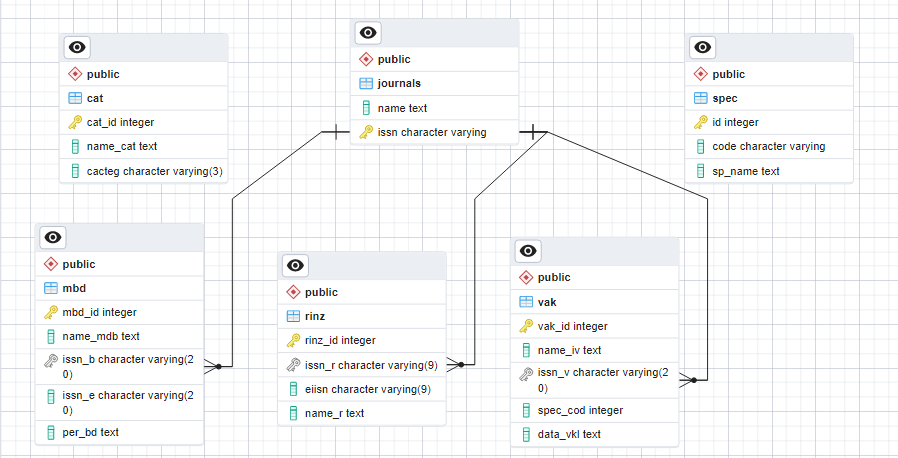
famsssss это ETL с нормализацией. Задача - типичная.
У тебя должен быть примерно такой план действий.
1)
Таблицы vak, ring, mdb, cat, spec нужно загрузить в БД как есть. В денормализованном виде. Если они лежат в excel - то сохранить их как CSV формат. Далее дело техники. Можете задать другой вопрос в qna по поводу того как их грузить.
2)
Надо нарисовать реляционную модель. Это примерно то что ты рисуешь в картинке но нужно рисовать от сущности-связи а не от того какие файлы даны. Например есть сущность ISNN. У нее есть какие-то атрибуты. Они возможно опциональные. Но они должны быть перечислены. Далее - другие сущности. Потом определяем связи между ними. Например если многим spec соотвествует один ISNN - то тип связи будет многие к одному. Бывает такое что между двумя сущностями связи многие-ко-многим. Как прямоугольная матрица где по горизонтали одна сущность а по вертикали - другая и на пересечении стоит YES когда связь в наличии. Это тоже можно. Это делается через промежуточную таблицу. Связи бывают рекурсивные (таблица может указывать сама на себя). И в РМ могут быть циклы и петли. Это тоже допускается. Просто в этом случае между сущностями будут несколько вариантов как их джойнить и все варианты верны.
3) После того как Реляционная Модель (РМ) определена - в
нее можно загружать данные. Можно грузить через INSERT/UPDATE/MERGE. И если возможностей не хватит то можно брать хранимые процедуры на Postgres. Но обычно мне хватало и SQL. В крайнем случае можно брать языки типа Python, Ruby e.t.c. если например доменная модель ооооочень сложная и надо какие-то делать неочевидные поиски по коллекциям или работать с JSON/XML но у тебя вроде все атомарно и лежит просто в ячейках. Должно хватить SQL.
4) Последняя таблица izdanya - по смыслу является отчетом из основной модели. Я настаиваю именно на таком подходе. Физически - это может быть view или таблица неважно. Главное что она - вторична по отношению к модели.


 Простой
Простой
 Средний
Средний