Создал таблицу с составным уникальным значением

Если в таблице есть запись
name = "имя"
region_id = 1
country_id = 1
то бд уже не разрешит повторно записать строчку с такими данными. Но проблема в том, что region_id может принимать значение null
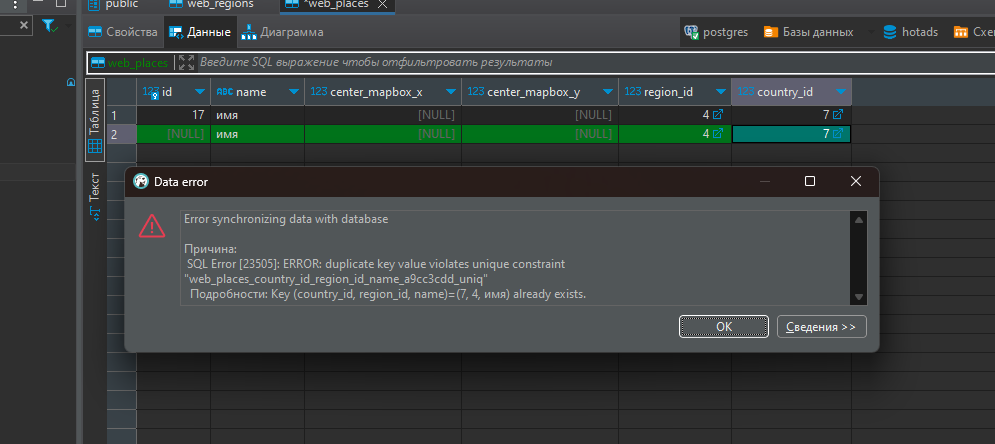
Например так все нормально определяется (такая запись уже есть и второй раз уже такое значение не пропускает )
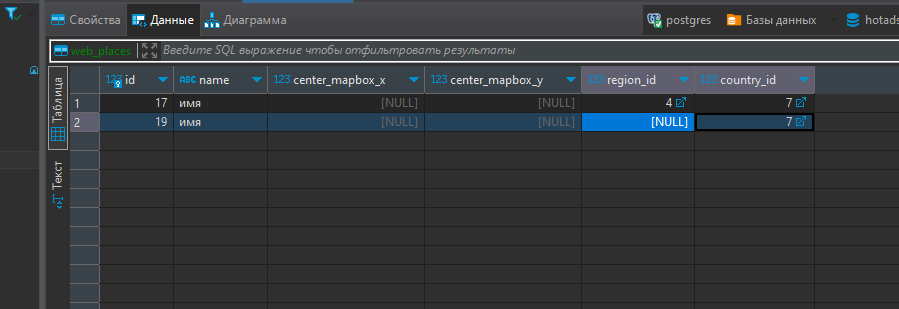
Так тоже нормально может создать значения потому что повторения нет
Но вот так уже не должен сохранять
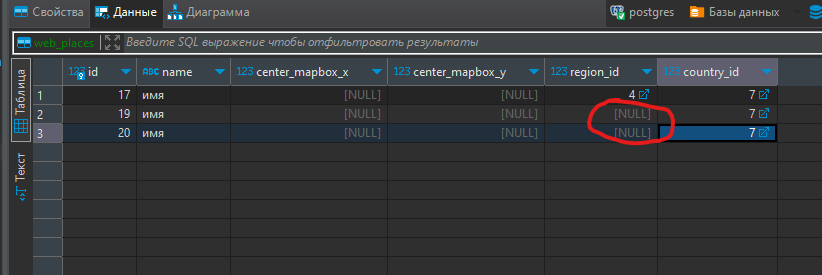
То есть он считает два null как разные значения. подскажите как быть в такой ситуации ?



 Простой
Простой
 Средний
Средний
