Пытаюсь выдрать из текста 3 подряд идущие перевода строки.
Перед этими 3-мя переводами стоит любое кол-во любых символов.
Попробовал создать такую регулярку:
[?<=\s\S](\n\n\n)
Но получаю что он находит 2 группы (см скрин ниже), в одной из групп он почему-то захватывает кроме 3 переводов строки еще и один ненужный мне символ.
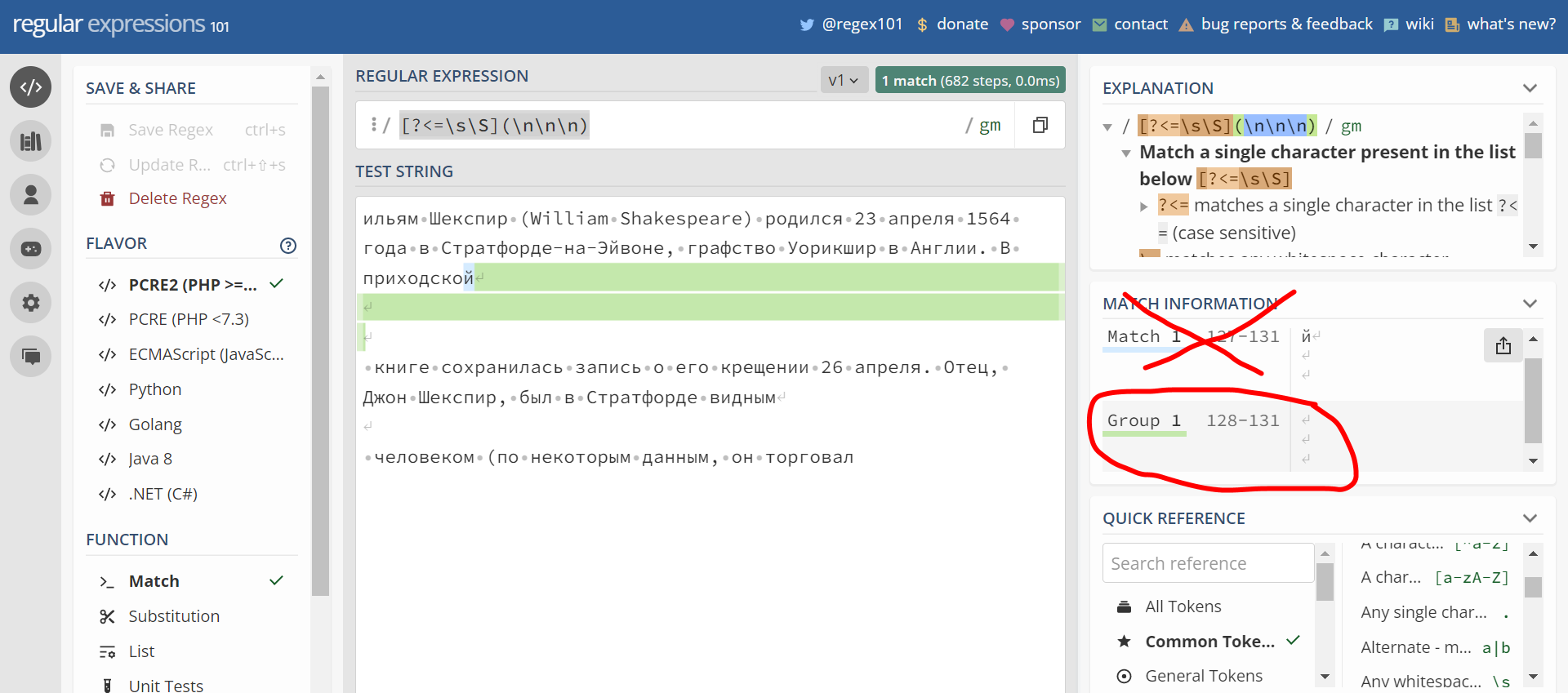
Что прописать чтоб регуляркой он находил только эти 3 подряд идущие перевода строки , то есть чтоб находил только одну группу которую я обвёл на скрине красным.
Ссылка на конструктор:
https://regex101.com/r/bYTm24/1 


 Простой
Простой

