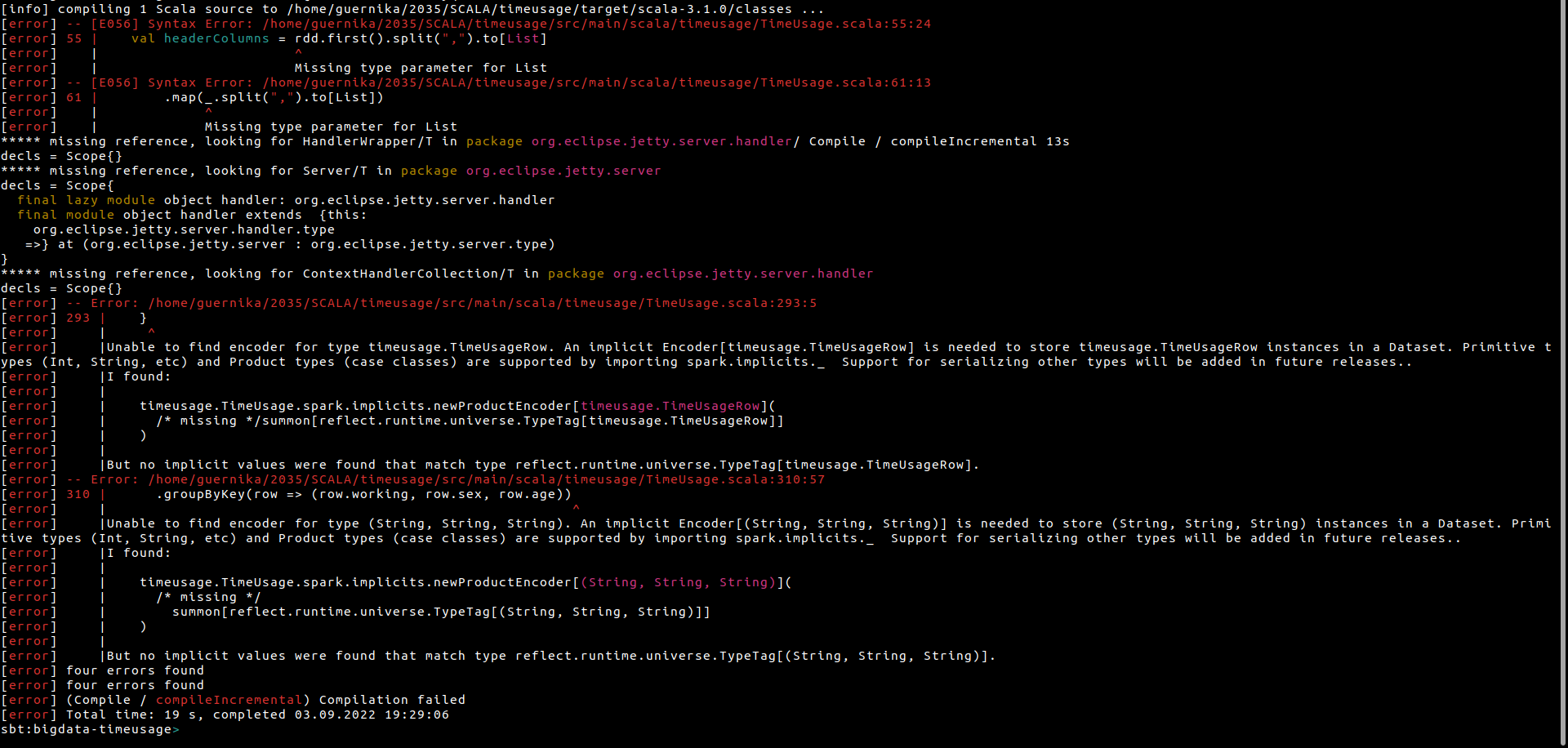
Код с ошибкой
def read(resource: String): (List[String], DataFrame) = {
val rdd = spark.sparkContext.textFile(fsPath(resource))
val headerColumns = rdd.first().split(",").to[List]
// Compute the schema based on the first line of the CSV file
val schema = dfSchema(headerColumns)
val data =
rdd
.mapPartitionsWithIndex((i, it) => if (i == 0) it.drop(1) else it) // skip the header line
.map(_.split(",").to[List])
.map(row)
val dataFrame =
spark.createDataFrame(data, schema)
(headerColumns, dataFrame)
}
Сам проект
https://disk.yandex.ru/d/8S5i3CfKj5z0SA
Датасет с описанием
https://www.kaggle.com/bls/american-time-use-survey
https://moocs.scala-lang.org/~dockermoocs/bigdata/... (164 Мб)
Цель .
Сколько времени занятые люди тратят на досуг по сравнению с безработными? (см. датасет)
Пошагово:
1. Прочитаем набор данных с помощью Spark;
CSV-файл в Spark-sql
https://spark.apache.org/docs/3.2.0/api/scala/org/...
def row(line: List[String]): Row = {
Row((line.head :: line.tail.map(_.toDouble)): _*)
}
2. Преобразуем его в промежуточный набор данных;
def classifiedColumns(columnNames: List[String]): (List[Column], List[Column], List[Column]) = {
def isPrimary(col: String): Boolean =
col.startsWith("t01") ||
col.startsWith("t03") ||
col.startsWith("t11") ||
col.startsWith("t1801") ||
col.startsWith("t1803")
def isWork(col: String): Boolean =
col.startsWith("t05") ||
col.startsWith("t1805")
def isOther(col: String): Boolean =
col.startsWith("t02") ||
col.startsWith("t04") ||
col.startsWith("t06") ||
col.startsWith("t07") ||
col.startsWith("t08") ||
col.startsWith("t09") ||
col.startsWith("t10") ||
col.startsWith("t12") ||
col.startsWith("t13") ||
col.startsWith("t14") ||
col.startsWith("t15") ||
col.startsWith("t16") ||
(col.startsWith("t18") && !(col.startsWith("t1801") || col.startsWith("t1803") || col.startsWith("t1805")))
(columnNames.filter(isPrimary).map(column), columnNames.filter(isWork).map(column), columnNames.filter(isOther).map(column))
}
3. Посчитать параметры для ответа на вопрос.
Реализуем метод timeUsageSummary, который сопоставит сформированный выше набор данных и общий набор данных. Получим 6 столбцов:
- workingStatusProjection рабочий статус,
- sexProjection пол,
- ageProjection возраст,
- workProjection количество ежедневных часов, затрачиваемых на основные виды деятельности,
- otherProjection количество ежедневных часов, затрачиваемых на работу, и количество ежедневных часов, затрачиваемых на иное
def timeUsageSummary(
primaryNeedsColumns: List[Column],
workColumns: List[Column],
otherColumns: List[Column],
df: DataFrame
): DataFrame = {
val workingStatusProjection: Column = when($"telfs" >= 1 && $"telfs" < 3, "working").otherwise("not working").as("working")
val sexProjection: Column = when($"tesex" === 1, "male").otherwise("female").as("sex")
val ageProjection: Column = when($"teage" >= 15 && $"teage" <= 22, "young").when($"teage" >= 23 && $"teage" <= 55, "active").otherwise("elder").as("age")
val primaryNeedsProjection: Column = primaryNeedsColumns.reduce(_ + _).divide(60).as("primaryNeeds")
val workProjection: Column = workColumns.reduce(_ + _).divide(60).as("work")
val otherProjection: Column = otherColumns.reduce(_ + _).divide(60).as("other")
df
.select(workingStatusProjection, sexProjection, ageProjection, primaryNeedsProjection, workProjection, otherProjection)
.where($"telfs" <= 4)
}
Посчитаем среднее значение по группировке в DataFrame Spark
def timeUsageGrouped(summed: DataFrame): DataFrame = {
summed.groupBy($"working", $"sex", $"age")
.agg(
round(avg("primaryNeeds"),1).as("primaryNeeds"),
round(avg("work"),1).as("work"),
round(avg("other"),1).as("other")
).orderBy($"working", $"sex", $"age")
}
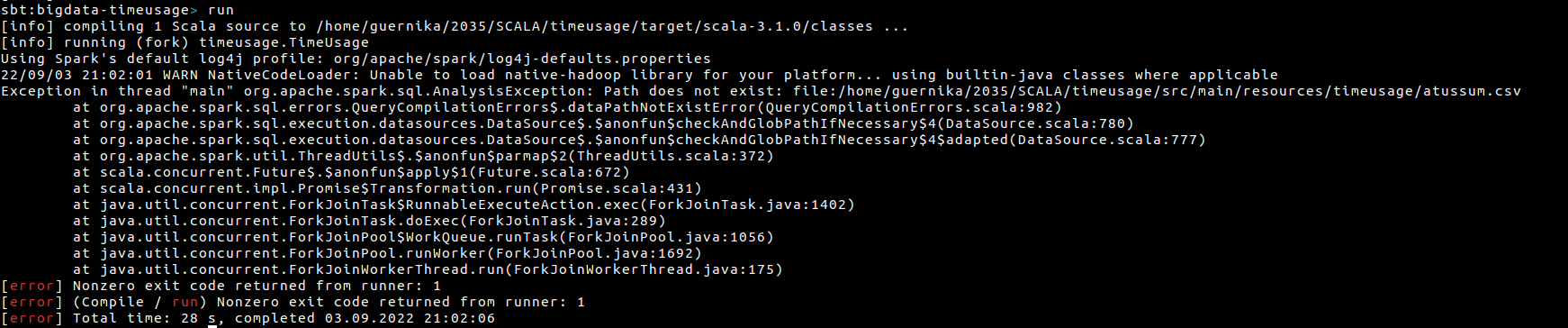
Если аккурат убрать всю обработку.... 0_о не хватает памяти?



 Сложный
Сложный
 Средний
Средний


