
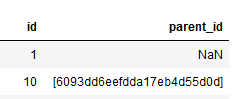
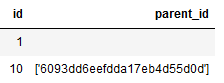

quoting: optional constant from csv module
Defaults to csv.QUOTE_MINIMAL. If you have set a float_format then floats are converted to strings and thus csv.QUOTE_NONNUMERIC will treat them as non-numeric.
 Простой
Простой
 Простой
Простой


