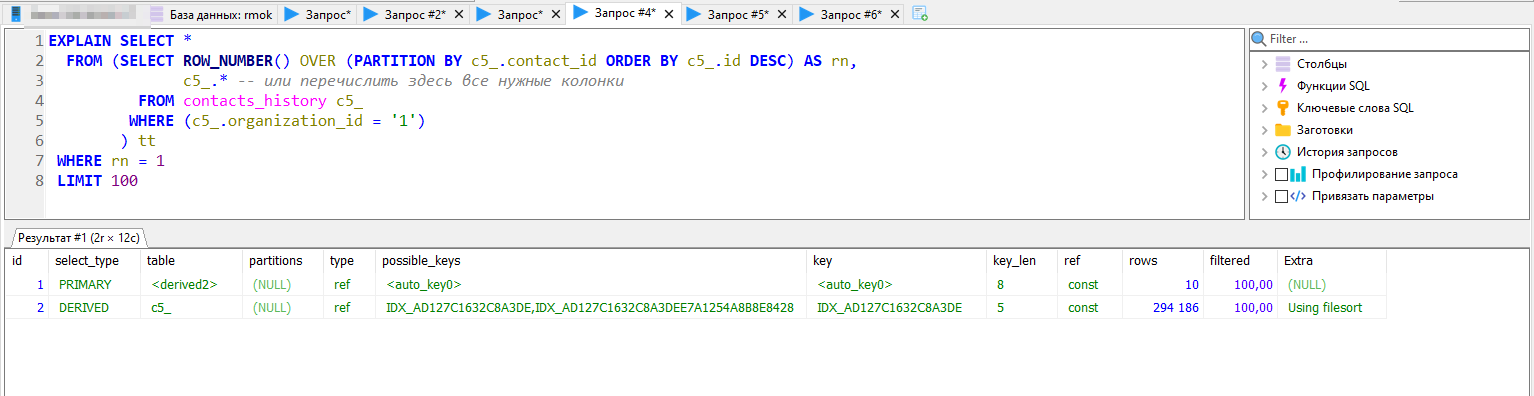
Будет разным количество столбцов, т.к. в первом случае select * производится из (подзапрос tt join таблица contacts_history), а во втором случае - только из таблицы contacts_history. То есть, в первом варианте будет плюс поле sclr_32.
По производительности мне эмпирически больше нравится первый вариант, но как выше правильно написал SagePtr, надо смотреть план, причем с реалистичным количеством строк и соотношением количества строк к количеству уникальных значений поля contacts_history.contact_id.
А если рассматривать применение подобных запросов на практике, то возможно, он еще будет обернут в select * from (...) limit xx offset yyy; Тогда и анализ надо будет проводить относительно полного текста. И тут мне кажется. первый вариант быстрее выдаст первые xx строк.