import threading
#pip install requests
import requests
def get_status(url, results):
results[url] = requests.get(url).status_code
sites = ['https://www.google.com/', 'https://www.youtube.com/',
'https://pastebin.com/', 'https://ru.wikipedia.org/',
'https://yandex.ru/', 'https://www.pornhub.com/',
'https://vk.com/', 'https://www.reddit.com/',
'https://qna.habr.com/', 'https://stackoverflow.com/']*5
results = {}
workers = [threading.Thread(target=get_status(sites[f], results)) for f in range(10)]
for worker in workers:
worker.start()
for worker in workers:
worker.join()
for k, v in results.items():
print(k, v)m = 3
simple_list = [1, 2, 3, 4]
res = []
for i in simple_list:
res += [i for _ in range(m)]
print(res)
# [1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4]n = 4
some_list = [6, 7, 8, 9]
replica = []
for i in some_list:
replica.append([i for _ in range(n)])
print(replica)
# [[6, 6, 6, 6], [7, 7, 7, 7], [8, 8, 8, 8], [9, 9, 9, 9]]Если форматирующие строки поступают от пользователей, то используйте шаблонные строки, чтобы избежать проблем с безопасностью. В противном случае используйте интерполяцию литеральных строк при условии, что вы работаете с Python 3.6+, и «современное» форматирование строк — если нет.
import requests
from bs4 import BeautifulSoup
from pprint import pprint
# %%time
list_nicknames = []
url = r"https://forum.excalibur-craft.ru/forum/14-флудилка/?page="
for i in range(1,228):
r = requests.get(url+str(i))
soup = BeautifulSoup(r.content)
all_rows = soup.find_all("div", {"class": "ipsDataItem_meta"})
for el in all_rows:
if el.find("a") is not -1 and el.find("a") is not None:
nickname = el.find("a").get_text()
list_nicknames.append(nickname)
uniq_nicknames = set(list_nicknames)
print(len(list_nicknames)) # 5671 пользователя
print(len(uniq_nicknames)) # 2126 уникальных
# pprint(uniq_nicknames)import requests
from bs4 import BeautifulSoup
from pprint import pprint
list_nicknames = []
url = r"https://forum.excalibur-craft.ru/forum/14-флудилка/?page="
for i in range(1,228):
r = requests.get(url+str(i))
soup = BeautifulSoup(r.content, "html.parser")
all_rows = soup.find_all("div", {"class": "ipsDataItem_meta"})
for el in all_rows:
if el.find("a") != -1 and el.find("a") is not None:
nickname = el.find("a").get_text()
list_nicknames.append(nickname)
uniq_nicknames = set(list_nicknames)
print(len(list_nicknames)) # 5671 пользователя
print(len(uniq_nicknames)) # 2126 уникальных
# pprint(uniq_nicknames)import requests
from bs4 import BeautifulSoup
from pprint import pprint
url = 'http://www.zagrya.ru/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
}
html = requests.get(url, headers=headers)
soup = BeautifulSoup(html.content)
# словарь, в который записываются НАЗВАНИЯ всех категорий на сайте и ССЫЛКИ на них
categories = {}
for cat in soup.find_all('a', {"class": "hor-menu__lnk"}):
name = cat.find("span", {"class":"hor-menu__text"}).get_text()
url = "http://www.zagrya.ru" + cat.attrs['href']
categories[name] = url
print(categories)
# {
# 'НОВИНКИ': 'http://www.zagrya.ru/category/category_2578/',
# 'КНИГИ': 'http://www.zagrya.ru/category/knigi/',
# 'ИГРУШКИ': 'http://www.zagrya.ru/category/igrushki/',
# 'КАНЦТОВАРЫ': 'http://www.zagrya.ru/category/category_2639/',
# 'УЧЕБНАЯ ЛИТЕРАТУРА': 'http://www.zagrya.ru/category/uchyebnaya-lityeratura/',
# 'ЭНЦИКЛОПЕДИИ': 'http://www.zagrya.ru/category/entsiklopyedii/',
# 'РАСПРОДАЖА': 'http://www.zagrya.ru/category/rasprodazha_1/'
# }
# словарь, в который записываются НАЗВАНИЯ всех категорий и их ПОДКАТЕГОРИИ
subcategories = {}
for k, v in categories.items():
# перебираем все ссылки/переходим по ним
html = requests.get(v, headers=headers)
soup = BeautifulSoup(html.content)
sub_list = []
for subcat in soup.find_all("div", {"class": "subcat-wrapper__item sub-cat-nobd"}):
sub_list.append(subcat.find("div", {"class": "sub-cat__title"}).get_text())
subcategories[k] = sub_list
# вывод на экран
for k,v in subcategories.items():
print(k)
pprint(v)
# Грошь - цена Вам, как специалисту, если Вы самостоятельно не разберётесь
# с тэгами и работай библиотек Requests и BeautifulSoupimport requests
from bs4 import BeautifulSoup
url = 'http://www.zagrya.ru/'
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36',
}
def get_html(url):
r = requests.get(url, headers=headers)
return r
def get_content(html):
soup = BeautifulSoup(html.content)
items = soup.find_all('li', {"class": "hor-menu__item has-subm"})
tovari = []
category = {}
for item in items:
tovari.append(item.find('a', {'class':'hor-menu__lnk'}).find('span', {'class':'hor-menu__text'}).get_text())
category['karegorii'] = tovari
return category
html = get_html(URL)
print(get_content(html))otzivi.extend(get_content(html.text))
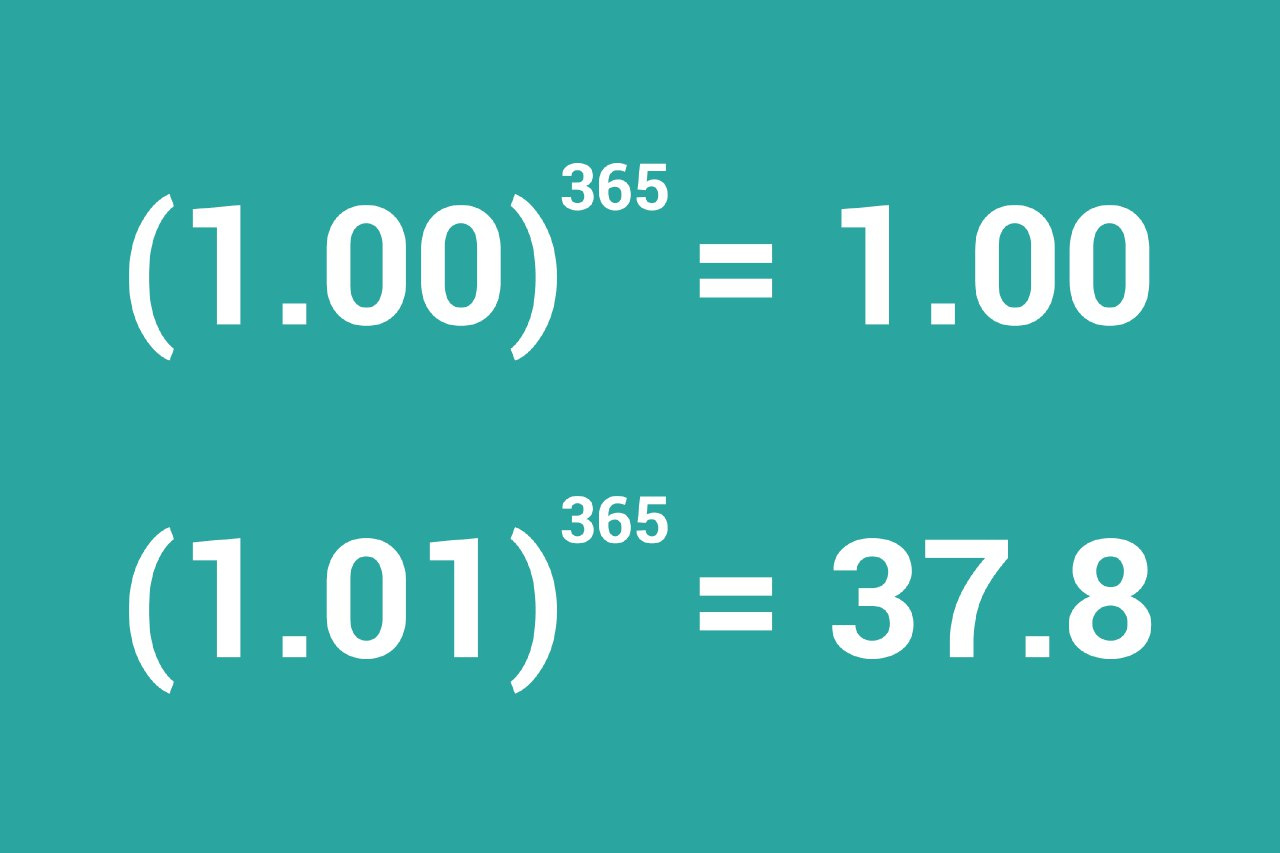

!pip list # поcсмотреть список всех установленных библиотек
!pip install zeep # установить библиотеку zeepg = ['a','b','c','d']
a = ""
for i in range(len(g)):
if i == 2:
a = a + ":" + g[i]
else:
a = a + g[i]
print(a)class Hero: # Класс "персонаж"
def __init__(self, dmg):
self.strength = 10
self.health = 300
self.damage = dmg * self.strength
def attacked(self):
self.damage += 1
def show(self):
print(f"strength: \t {self.strength}")
print(f"health: \t {self.health}")
print(f"damage: \t {self.damage}")
bolg = Hero(dmg=1000) # создаём орка
aragorn = Hero(dmg=800) # создаём рыцаря
# выводим на экран характеристики героев:
bolg.show()
print()
aragorn.show()
# начинаем битву
bolg.attacked()
aragorn.attacked()
# снова выводим на экран характеристики героев:
bolg.show()
print()
aragorn.show()
# и так далее...from bs4 import BeautifulSoup
html = '<a class="bttn_green" href="/index.php?r=quests/reward&id=74538347&quest_id=1598044167">text</a> \
<a class="bttn_green" href="/index.php?r=quests/reward&id=74498540&quest_id=1597875696">text</a> \
<a class="bttn_green" href="/index.php?r=quests/reward&id=74205167&quest_id=1596578514">text</a> \
<a class="bttn_green" href="/index.php?r=quests/reward&id=74479806&quest_id=1597790754">text</a> \
<a class="bttn_green" href="/index.php?r=quests/reward&id=74327918&quest_id=1597093800">text</a>'
soup = BeautifulSoup(html)
links = soup.findAll("a", {"class": "bttn_green"})
for link in links:
# print(link.get_text())
print(link.attrs["href"])for account in file:
if account.count(":") == 3:
username = account.split(":")[0]
passwords = account.split(":")[1]
code = account.split(":")[2]
else:
print("code is absent")
username = account.split(":")[0]
passwords = account.split(":")[1]