

detSimilarity(w1, w2) != detSimilarity(w2, w1)
06 | 03 | 01
-------------
03 | 05 | 02
-------------
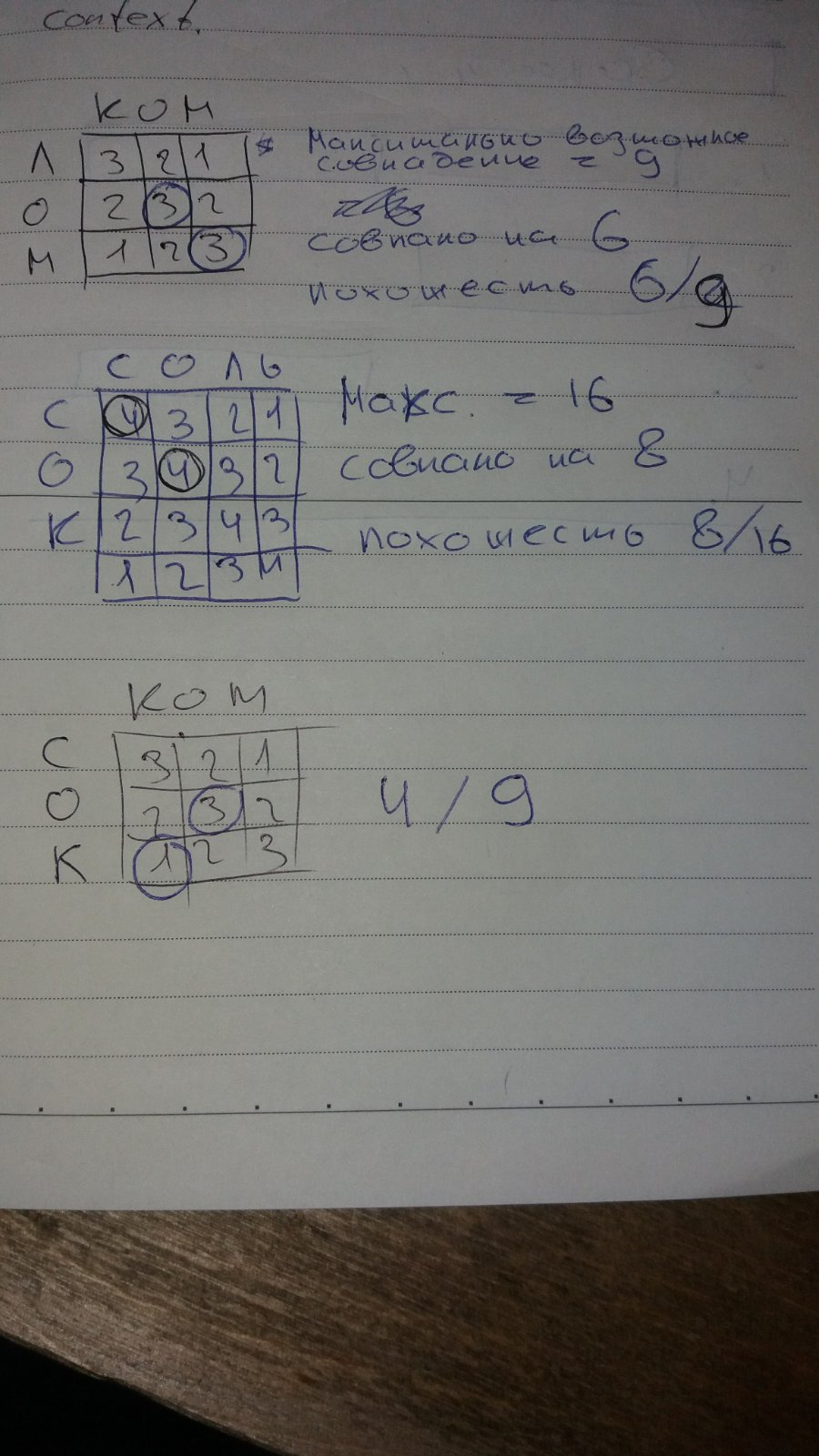
01 | 02 | 04сом однозначно отойдет ко второй группе
ком, лом, ром, сомсок, сом, сор и возможно сольлосьсом, которая равноудалена от слов как первой так и второй групп, к какой группе его отнести? к первой, второй, а может сразу к обоим группам? Математически оно одинаково близко к обоим группам.function detSimilarity(w1, w2) {
const len = Math.max(w1.length, w2.length);
let summ = 0;
for (let i1 in w1) {
c1 = w1[i1];
let d = len;
for (let i2 in w2) {
c2 = w2[i2];
if (c1 == c2) {
const t = Math.abs(i1 - i2);
if (t < d) d = t;
}
}
summ += len - d;
}
return summ / Math.pow(len, 2);
}
При том, что "вес" каждого слова до кластеризации должен быть уникальным.
Как именно можно создать 3 кластера похожих по написанию слов из следующего ниже списка слов:
А можно пример? Ну конечно. Предположим, у нас есть набор данных пациентов. В кластерном анализе они называются признаками. О каждом из пациентов нам известны различные факты: возраст, пульс, кровяное давление, уровень холестерина, и т.д. Это вектор характеристик, представляющий пациента.
[значение признака 1, значение признака 2, ...., значение признака N]Bavashi, о, еще один (вы) не понимает разницы в векторах атаки.
хэширование пароля на клиенте делают не для того, чтобы его украли по дороге на сервер (MITM).
Это делают для того, чтобы на сервере пароль никогда не появлялся даже при регистрации.
Если же мы говорим о взломе сервера и угоне хэшей - если хэшей не будет совсем, злоумышленник получит все пароли сразу. Даже просто засунутые в md5 пароли уже потребуют от него минимальной квалификации, а сделанные "правильно (соль + злая функция)" - практически лишат шансов на успех.
const pup = require('puppeteer');
const fs = require('fs');
const user = {
name: '+38063 333 3333',
pass: '111111111111'
};
const parse = async () => {
try {
let browser = await pup.launch({headless: false});
let page = await browser.newPage();
await page.goto('https://easypay.ua/ua/profile/wallets');
await page.focus(`input[type="tel"]`)
await page.keyboard.type(`${user.name}`)
await page.focus(`input[type="password"]`)
} catch (e) {
console.error(e)
}
}
parse();await page.focus(`input[type="password"]`)
Error: Node is either not visible or not an HTMLElement
at ElementHandle._clickablePoint (/home/roman/work/puppeteer/node_modules/puppeteer/lib/cjs/puppeteer/common/JSHandle.js:337:19)
at processTicksAndRejections (internal/process/task_queues.js:97:5)
at async ElementHandle.click (/home/roman/work/puppeteer/node_modules/puppeteer/lib/cjs/puppeteer/common/JSHandle.js:390:26)
at async DOMWorld.click (/home/roman/work/puppeteer/node_modules/puppeteer/lib/cjs/puppeteer/common/DOMWorld.js:277:9)
at async parse (/home/roman/work/puppeteer/app.js:18:9)