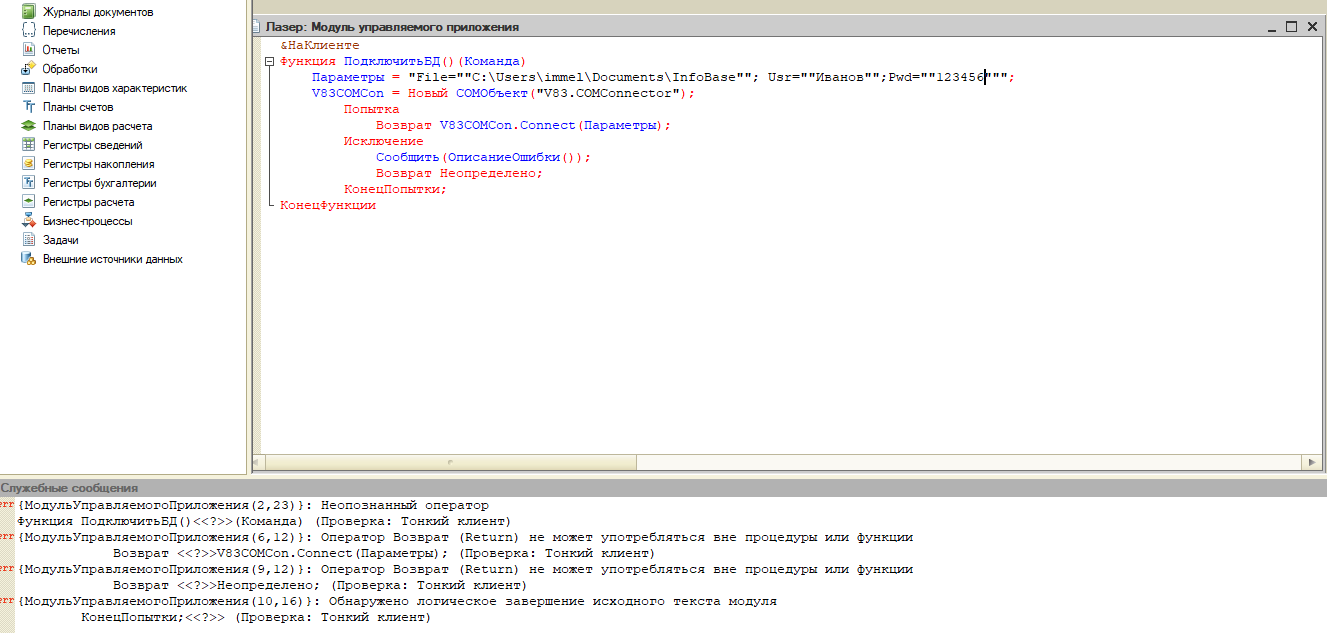
Дмитрий Кинаш, выяснил, что запись в реквизит, связанный с полем выбора, происходит. Дело в другом. При открытии формы элемента справочника в поле выбора не отображается значение реквизита. При этом, в поле ввода значение соответствующего ему реквизита отображается. Как мне сделать, чтобы и в поле выбора отображалось сохраненное значение реквизита?
Почему, когда я в форме элемента справочника в поле выбора выбираю значение, затем нажимаю OK, а затем заново открываю форму элемента, то поле выбора пустое? Почему выбранное значение не сохраняется?
Спасибо! С этим разобрался. Пишу просто "Организация.Наименование КАК ORG".
А как можно "прочитать" поля табличной части возвращенных запросом документов?
Мне нужно в python-скрипте обходить документы и анализировать их табличную часть.
Или может быть нужно действовать иначе? Например, первым запросом вернуть GUID на отобранные документы, а затем для каждого GUID отправлять запрос на табличную часть?
Сергей Горностаев, ///Из этого может следовать два вывода - либо источник информации был плохой, либо вы к этой информации неготовы.///
Ни то, ни другое. В лекции об этом было сказано вскользь и без примеров.
Господа, я, конечно, благодарен всем за заботу и методические рекомендации, но кто-нибудь может высказаться сугубо по теме заданного вопроса?
Цель – маркировать каждую единицу отгружаемого продукта для отслеживания гарантийных случаев.
Генерировать серийные номера нужно при создании документа "Заказ на производство". Например, покупатель хочет купить 1000 лампочек. Сначала создается документ "Заказ покупателя" с одной позицией "Лампочка – 1000 шт.". А потом на основании "Заказ покупателя" создается документ "Заказ на производство", в котором генерируется 1000 серийных номеров, которые впоследствии отправляются на лазерную установку для маркировки.