Во-вторых, осмысленность таким комбинациям дают связи между данными, для обработки которых, внезапно, придуманы реляционные базы данных.для этого у вас должна быть БД и вы её должны написать и хранить, так же она индивидуальна, мне же именно что нужно найти общее или скорее универсальное решение.
А в-нулевых, вас так кидает по вопросу, что, похоже, отвечать на него не имеет смысла, поскольку вопроса просто-напросто нет. Теория всего какая-то, а скорее - просто каша в голове вместо задачи.Каша? Наверное, не каша писать про перебор, когда написано, что мне нельзя его использовать, не каша цепляться к словам «словарь» и «буквы», когда я ответил, что они будут заменены, не каша вести себя так как будто я обязал ответить на вопрос именно вас. Я не собираюсь с вами спорить, в вашем мире вы всегда правы, зачем что-то менять?
вы ищете какое-то абстрактное решение непонятно чего.
А в этой конкретной предметной области все упирается в словарь.
Не имеющий никакой логики, кроме собственно конечного списка.
Также мне нельзя использовать метод перебора, который прям напрашивается сюда
И уж в любом случае - статистика в лингвистике так не работает, можете не натягивать. Ни на буквах, ни на словах.Я, конечно, не в коем случае не эксперт, но, аж загуглив, можно получить следующее.
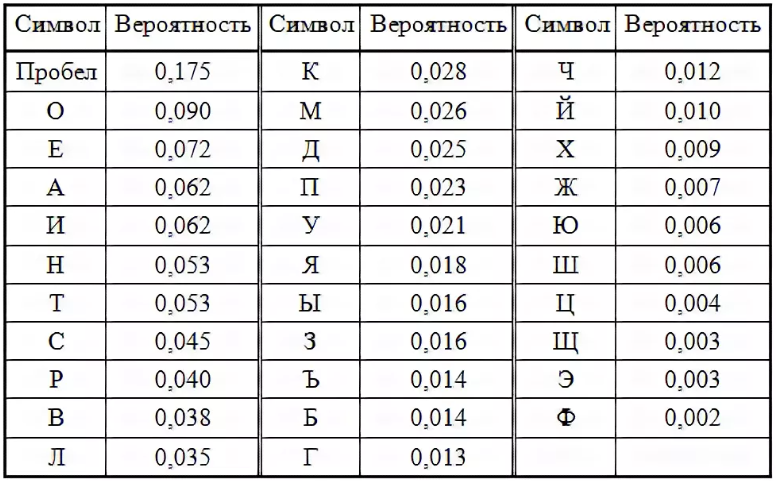
Ну, составьте списки в памяти: слов, которые накрываются каждым из массивов, если он будет первым; слов, которые накрываются каждым вариантом второго массива, третьего и четвертого. Получите полный набор вариантов без перебора.Вы предлагаете своего рода фильтрацию, которая действительна до тех пор, пока буквы будут буквами, если буквы заменить словами, а словарь — книгой, то мне нужно будет переделывать «фильтр» (да я прекрасно понимаю, что в случае с вероятностью программа будет странной и не особо понятной, вроде того, что вероятность того, что буква а используется с буквой б в слове, не равна вероятности использования комбинации объектов в контексте регулирующего объекта), мне же нужно, чтобы этот «фильтр» был действителен и при замене данных.
все эти частности про пробелы и твердые знаки - щебень и экономия на спичках.экономия должна быть экономной, извините не удержался )
например, мягкий и твёрдый знаки в первой позиции, из таких же логичных тенденций то пробел на второй позиции тоже приведёт к негативным последствиям. Только эти тенденции нужны не для нас с вами, а для самой машины. Опять-таки, в задаче подразумевается замена букв какими-то другими данными (я действительно не могу сказать, какими), замена словаря другим регулирующим объектом, и чтобы, я так понимаю, система сама смогла понять, какие комбинации данных имеют смысл в контексте N регулирующего объекта, а какие нет.