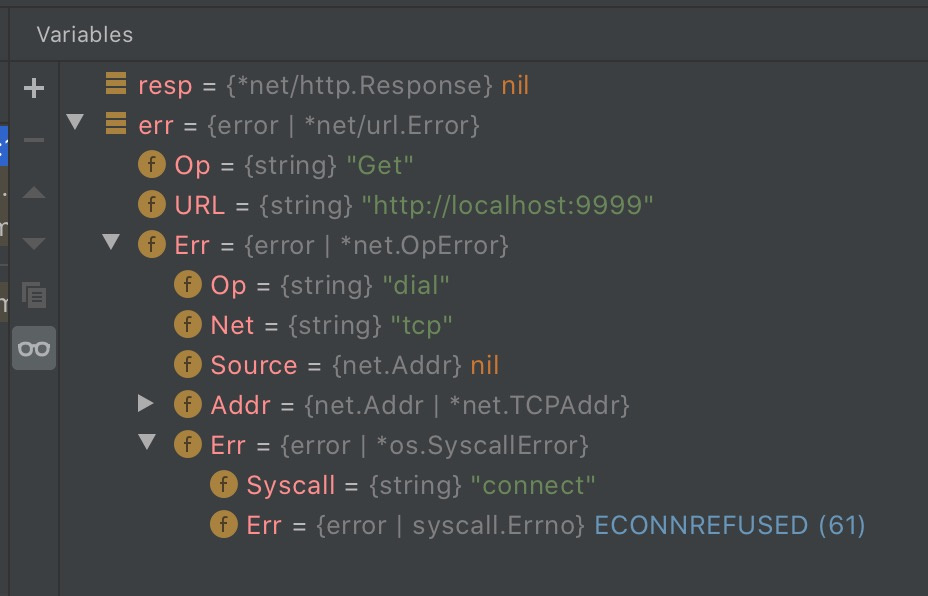
...
transport := &http.Transport{TLSClientConfig: tlsConfig}
client := &http.Client{Transport: transport}
resp, err := client.Post(...)
...func httpRequest(waitChan chan struct{}, inputData inputDataStruct) {
//url := <- urlChan
defer close(waitChan)
urlChan := make(chan string)
count := inputData.count
j := 0
var wg sync.WaitGroup
for i := range inputData.url {
for j < count {
wg.Add(1)
go func() {
getResponse(urlChan, inputData)
wg.Done()
}
urlChan <- inputData.url[i]
j++
}
j = 0
}
wg.Wait()
}If the paths=source_relative flag is specified, the output file is placed in the same relative directory as the input file. For example, an input file protos/buzz.proto results in an output file at protos/buzz.pb.go.
var _ = fmt.Println
var _ = myvarNow that ioutil is no longer needed, and os was already imported, we have one less dependency
Черновики дизайна это даже не предложения (proposals), с которых начинается любое изменение в библиотеке, тулинге или языке Go. Это начальная точка для обсуждения дизайна, предложенная командой Go после нескольких лет работы над данными вопросами. Всё, что описано в черновиках с большой долей вероятности будет изменено, и, при наилучших раскладах, воплотится в реальность только через несколько релизов (я даю ~2 года).
Если не сложно, посоветуйте как лучше обрабатывать ошибки, так как у меня в коде копипаст из обработчика ошибки, вот например:
// WithoutCancel returns a context that is never canceled.
func WithoutCancel(ctx context.Context) context.Context {
return noCancel{ctx: ctx}
}
type noCancel struct {
ctx context.Context
}
func (c noCancel) Deadline() (time.Time, bool) { return time.Time{}, false }
func (c noCancel) Done() <-chan struct{} { return nil }
func (c noCancel) Err() error { return nil }
func (c noCancel) Value(key interface{}) interface{} { return c.ctx.Value(key) }package main
import (
"context"
"time"
)
func main() {
ctx := context.Background()
ctx, c := context.WithTimeout(ctx, 100*time.Millisecond)
defer c()
ctxNo := WithoutCancel(ctx)
...
}type Post struct {
ID int64
Title string
Text string
}
type UserPosts struct {
Username string
Posts []Post
}
func qna864719(db *sql.DB) ([]UserPosts, error) {
query := `select u.username
, p.post_id
, p.post_title
, p.post_text
from posts p
join users u on u.user_id = p.post_author
group by u.username, p.post_id;`
rows, err := db.Query(query)
if err != nil {
return nil, fmt.Errorf("query: %w", err)
}
defer rows.Close()
var result []UserPosts
for rows.Next() {
var username string
var post Post
err = rows.Scan(&username, &post.ID, &post.Title, &post.Text)
if err != nil {
return nil, fmt.Errorf("scan: %w", err)
}
// Здесь логика преобразования результата в массив UserPosts
}
err = rows.Err()
if err != nil {
return nil, fmt.Errorf("after scan: %w", err)
}
return result, nil
}func qna864719_1(db *sql.DB) ([]UserPosts, error) {
query := `select u.username
, p.post_id
, p.post_title
, p.post_text
from posts p
join users u on u.user_id = p.post_author
group by u.username, p.post_id
order by u.username` // <-------- ОБЯЗАТЕЛЬНАЯ СОРТИРОВКА
rows, err := db.Query(query)
if err != nil {
return nil, fmt.Errorf("query: %w", err)
}
defer rows.Close()
var result []UserPosts
// Храним промежуточный результат по юзеру в переменной,
// перед добавлением в основной массив
var lastResult *UserPosts // <--------
for rows.Next() {
var username string
var post Post
err = rows.Scan(&username, &post.ID, &post.Title, &post.Text)
if err != nil {
return nil, fmt.Errorf("scan: %w", err)
}
// Здесь логика преобразования результата в массив UserPosts
// Если промежуточный результат существует, но username отличается
// от текущего, то добавляем промежуточный результат в основной массив
// обнуляя промежуточный результат
if lastResult != nil && lastResult.Username != username {
result = append(result, *lastResult)
lastResult = nil
}
// Если промежуточного результата нет, иницилизируем его
if lastResult == nil {
lastResult = &UserPosts{Username: username}
}
// Добавляем посты
lastResult.Posts = append(lastResult.Posts, post)
}
err = rows.Err()
if err != nil {
return nil, fmt.Errorf("after scan: %w", err)
}
// После выхода из сканирования, у нас может остаться промежуточный результат
// который необходимо добавить в основной массив
if lastResult != nil {
result = append(result, *lastResult)
}
return result, nil
}func qna864719_2(db *sql.DB) ([]UserPosts, error) {
query := `select u.username
, p.post_id
, p.post_title
, p.post_text
from posts p
join users u on u.user_id = p.post_author
group by u.username, p.post_id;`
rows, err := db.Query(query)
if err != nil {
return nil, fmt.Errorf("query: %w", err)
}
defer rows.Close()
var result []UserPosts
// Иницилизируем хеш-мап который будет содержать посты по username
postsByUsername := make(map[string][]Post)
for rows.Next() {
var username string
var post Post
err = rows.Scan(&username, &post.ID, &post.Title, &post.Text)
if err != nil {
return nil, fmt.Errorf("scan: %w", err)
}
// Здесь логика преобразования результата в массив UserPosts
// Добавляем посты в мап
postsByUsername[username] = append(postsByUsername[username], post)
}
err = rows.Err()
if err != nil {
return nil, fmt.Errorf("after scan: %w", err)
}
// Преобразовываем мап в массив
for username, posts := range postsByUsername {
result = append(result, UserPosts{
Username: username,
Posts: posts,
})
}
// Сортируем, так как в мапе записи хранятся в "случайном" порядке
sort.Slice(result, func(i, j int) bool {
return result[i].Username < result[j].Username
})
return result, nil
}