

% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 1370 0 1370 0 0 4598 0 --:--:-- --:--:-- --:--:-- 4612
{
"data": [
{
"block_number": 14384879,
"date": 1647263052,
"hash": "0x72d3a499e38b26a7ac6f77955a5aad3c824e39794c2b649c32f6d8ec7bcbc416",
"miner": null,
"status": 11,
"value": 1.75
},
{
"block_number": 14384870,
"date": 1647262953,
"hash": "0x1563ee582ffd0a7ed7dbf3e09b894003ae9e13cda6f12ef17428a0c1e4f1f3d0",
"miner": "0x8bc7a21a1f3a2d3e9ae872077765a0e6f59c7822",
"status": 1,
"value": 2.03091155084
},
{
"block_number": 14384852,
"date": 1647262735,
"hash": "0x7a13f3a686db6dae25f0ab8507efffdd869ad26a90e9f2c74d779957c6f9b628",
"miner": "0x11bad4e093b8fb9f951dca8e5ec9474694ad4d6e",
"status": 1,
"value": 2.14722100253
},import re
data = '''ID: 3
Каталог: Самсон
Название категории: Бумага белая марок А, В, С
Родители категории: Офис / '''
out = re.sub(' +', ' ', data)
print(out)
#ID: 3
# Каталог: Самсон
# Название категории: Бумага белая марок А, В, С
# Родители категории: Офис /import json
import re
json_dump = re.search(r'JSON.parse\(\'({.*})?\'\)', src)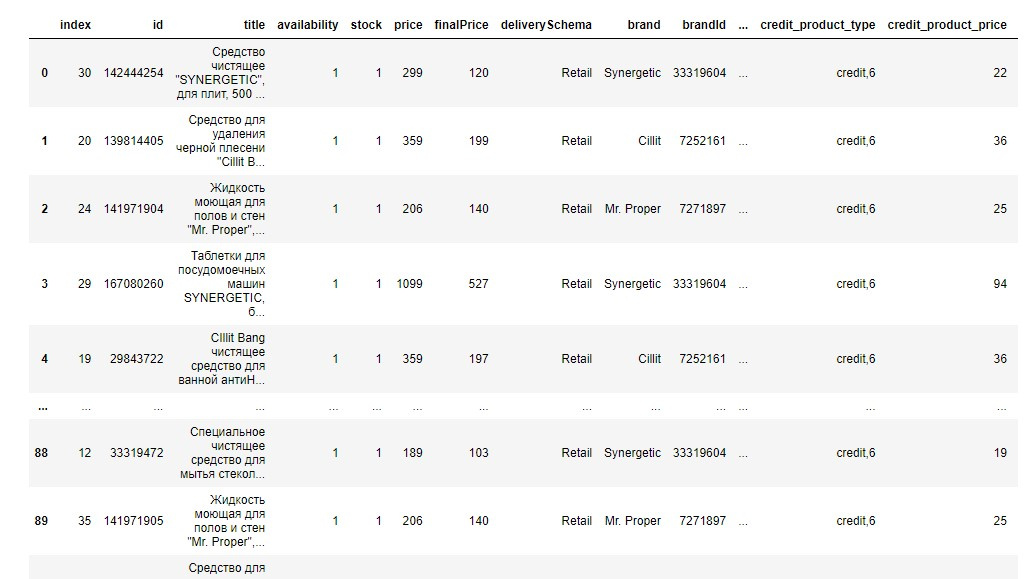
import io
from lxml import etree
parser = etree.HTMLParser()
html = '''
<div class='user-data__about'>
<strong>UI/UX and Product Designer<br><br></strong><strong>Портфолио<br></strong>alexandr</a> > <a works</a><br>Экспертная область — дизайн мобильных приложений и web-интерфейсов.<br>Рисую дизайн для сайтов, мобильных и web-приложений. <br>Работаю с компаниями, студиями, стартапами.<br><br>Мне нравиться создавать поистине крутой продуктовый дизайн для своих клиентов. Погружаться в бизнес логику продукта и улучшать его качество. При этом развиваться как профессионал и оттачивать мастерство в любимом деле.<br><br><br><strong>Ссылки</strong><br><br><br><strong>Контакты</strong><br><strong><br>Услуги</strong><br><ul><li>UI/UX дизайн мобильных приложений и web-интерфейсов.</li><li>Адаптивный дизайн сложных CRM, SaaS(дашборды аналитики, таблицы)</li><li>Отрисовка иллюстраций.</li><li>Анимация интерфейсов.</li><li>Сотрудничество под NDA.</li></ul><br><strong>Инструменты</strong><br><ul><li>Figma</li><li>Sketch</li><li>After Effects</li></ul><strong><br>Примеры лучших работ<br></strong><br>Дизайн сайтов<br><br>Дизайн мобильных приложений<br>
</div>
'''
root = etree.parse(io.StringIO(html), parser=parser)
print(' '.join(root.xpath('.//text()')))import lxml.html
root = lxml.html.fromstring(html)
print([x.get('title') for x in root.xpath('.//td/div')])['Ясно', 'Ясно', 'Облачно с прояснениями', 'Облачно с прояснениями', 'Облачно с прояснениями',
'Облачно с прояснениями, дождь', 'Облачно с прояснениями, дождь', 'Облачно с прояснениями']driver.get('http://lenta.ru')
driver.execute_script('''
var aTags = document.getElementsByTagName("a");
for (var i = 0; i < aTags.length; i++) {
if (aTags[i].innerText.startsWith("07:50Опубликованы данные")) {
aTags[i].innerText = "Утки с Марса захватили вселенную!";
break;
}
}
''')
time.sleep(1)
screenshot = driver.get_screenshot_as_png()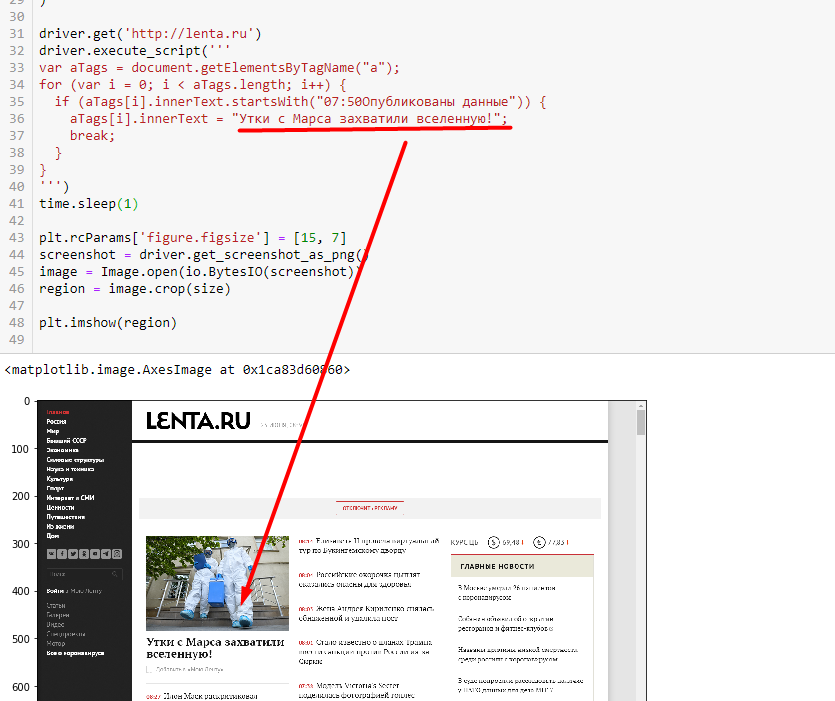
>>> stroka = """<td class="text" align="center" style="font-family: Arial, sans-serif; color:#646464; font-size: 13px; line-height: 15px; text-decoration: line-through;">
... <span style="font-family: Arial, sans-serif; color:#646464; font-size: 13px; line-height: 15px; text-decoration: line-through;">
... 53.63 Р<!-- <span class="oldprice4">53,63</span> -->
... </span>
... </td>"""
>>> from lxml import etree
>>> from io import StringIO
>>> parser = etree.HTMLParser()
>>> tree = etree.parse(StringIO(stroka), parser)
>>> tree.xpath('.//td/span')[0].text
'\n 53.63 Р'>>> tree.xpath('.//td/span')[0].text.replace('\n','').strip()
'53.63 Р'