

у меня каждый раз ломается json
import json
data = '''{
"id": {
"login": "login",
"password": "password"
}
}'''
json_data = json.loads(data)
json_data['1'] = {'login': 'log', 'password': 'pass'}
print(json.dumps(json_data, indent=4))
# {
# "id": {
# "login": "login",
# "password": "password"
# },
# "1": {
# "login": "log",
# "password": "pass"
# }
# }from fuzzywuzzy import fuzz
files = ['новая папка', 'games', 'install', 'фото', 'музыка']
search = ['папка', 'фотки', 'музло']
result = []
for im in search:
for fil in files:
if fuzz.partial_ratio(im, fil) > 50:
result.append(fil)
print(result)
# ['новая папка', 'фото', 'музыка']TIMESTAMP=`date +"%Y-%m-%d_%H-%M-%S"`
...
getdays = ban[0]
ban1 = datetime.strptime(getdays, "%Y-%m-%d")
...langs = ['en-us', 'en-mc', 'en-gb', 'en-im', 'en-je', 'en-vg', 'en-ie', 'en-lu', 'sv-se', 'en-by', 'en-md', 'en-al', 'en-xk', 'en-me', 'fr-fr', 'fr-bl', 'fr-ch', 'es-es', 'it-it', 'it-sm', 'pt-pt', 'de-de', 'de-at', 'de-li', 'de-ch', 'nl-nl', 'nl-be', 'en-no', 'en-sj', 'en-fi', 'en-ax', 'en-dk', 'en-gl', 'en-is', 'ru-ru', 'pl-pl', 'bg-bg', 'cs-cz', 'el-gr', 'hu-hu', 'lt-lt', 'ro-ro', 'sk-sk', 'uk-ua', 'en-lv', 'en-rs', 'en-si', 'en-ba', 'en-cy', 'en-ee', 'en-hr', 'en-mk', 'en-mt', 'en-ph', 'en-mm', 'en-kh', 'en-mn', 'en-kz', 'en-la', 'en-za', 'en-ck', 'fr-ca', 'en-au', 'en-nz', 'es-ar', 'es-gt', 'es-do', 'es-hn', 'es-ni', 'es-pa', 'es-ec', 'es-py', 'es-ve', 'en-ae', 'en-lb', 'en-il', 'en-pk', 'id-id', 'tr-tr', 'ko-kr', 'th-th', 'en-ca', 'es-co', 'en-sg', 'zh-hk', 'zh-cn', 'en-in', 'en-bd', 'en-lk', 'en-np', 'en-mv', 'pt-br', 'es-pe', 'en-hk', 'ar', 'es-mx', 'ja-jp', 'en-my', 'vi-vn', 'zh-tw', 'en-se']
out_langs = []
for lang in langs:
if not lang.split('-')[0] in [x.split('-')[0] for x in out_langs]:
out_langs.append(lang)
print(out_langs)
# ['en-us', 'sv-se', 'fr-fr', 'es-es', 'it-it', 'pt-pt', 'de-de', 'nl-nl', 'ru-ru', 'pl-pl', 'bg-bg', 'cs-cz', 'el-gr', 'hu-hu', 'lt-lt', 'ro-ro', 'sk-sk', 'uk-ua', 'id-id', 'tr-tr', 'ko-kr', 'th-th', 'zh-hk', 'ar', 'ja-jp', 'vi-vn']langs = ...
out_langs = []
current_lang = None
for lang in sorted(langs):
if current_lang != lang.split('-')[0]:
out_langs.append(lang)
current_lang = lang.split('-')[0]
print(out_langs)
# ['ar', 'bg-bg', 'cs-cz', 'de-at', 'el-gr', 'en-ae', 'es-ar', 'fr-bl', 'hu-hu', 'id-id', 'it-it', 'ja-jp', 'ko-kr', 'lt-lt', 'nl-be', 'pl-pl', 'pt-br', 'ro-ro', 'ru-ru', 'sk-sk', 'sv-se', 'th-th', 'tr-tr', 'uk-ua', 'vi-vn', 'zh-cn']/opt/Python-3.8.7/proj/bin/python
wordlist = [
'Маша', 'Игорь', 'Светлана', 'Евгений'
]
text = '''Задача организации, в особенности же разбавленное изрядной долей эмпатии,
рациональное мышление обеспечивает широкому кругу (специалистов) Светлана Евгений Маша Игорь
участие в формировании инновационных методов управления процессами.
В своём стремлении улучшить пользовательский опыт мы упускаем, что некоторые особенности внутренней
политики могут быть своевременно верифицированы.'''
result = []
for word in text.split():
if word in wordlist:
result.append(word)
print(result)
# ['Светлана', 'Евгений', 'Маша', 'Игорь']import cv2
import matplotlib.pyplot as plt
data = [
['255', '255', '255', '190', '190', '160', '76', '45', '78'],
['255', '255', '255', '190', '190', '160', '76', '45', '78'],
['255', '255', '255', '190', '190', '160', '76', '45', '78']
]
to_chunks = lambda x, n:[x[i*n:i*n+n] for i in range(len(x) // n)]
img = [to_chunks(list(map(int, row)), 3) for row in data]
f,ax = plt.subplots(1,1)
ax.imshow(img)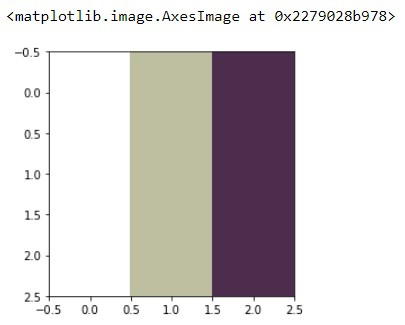
let url = process.argv[2]
var Nightmare = require('nightmare');
var nightmare = Nightmare({show: false,webPreferences: {}})
nightmare
.goto(url)
.viewport(1600, 900)
.wait(5000)
.evaluate(function() {
return document.documentElement.innerHTML;
})
.end()
.then(res => {console.log(res)});tar ... && touch success.flagесть более надежные архиваторы, чтоб если соединение потеряно, то он все равно сам архив доделает
import json
import re
json_dump = re.search(r'JSON.parse\(\'({.*})?\'\)', src)
[1, 3, 5, 6, 6, 6, 7, 70]
0, 1, 2, 3, 4, 5, 6, 7 # позиции элементов
элемент посредине - это 6 на позиции 3.
Сравниваем с 20. 20 больше 6
Значит слева от 6-ки смотреть числа смысла нет - это числа [1, 3, 5].
Сама 6 тоже не нужна - мы ее уже сравнили с искомым и уже узнали что это не то число.
Значит берем часть списка справа -
с позиции +1 - то есть с 4-й позиции и до конца - [6, 6, 7, 70]
и т.п.